MongoDB在C#中使用
示例
1 | using MongoDB.Bson; |
公共类
做通用查询的时候,可以使用。
1 | /// <summary> |
1 | using MongoDB.Bson; |
做通用查询的时候,可以使用。
1 | /// <summary> |
作为一个数据库,基本的操作就是 CRUD。MongoDB 的 CRUD,不使用 SQL 来写,而是提供了更简单的方式。
BsonDocument方式
BsonDocument 方式,适合能熟练使用 MongoDB Shell 的开发者。MongoDB Driver 提供了完全覆盖 Shell 命令的各种方式,来处理用户的 CRUD 操作。
这种方法自由度很高,可以在不需要知道完整数据集结构的情况下,完成数据库的CRUD操作。
数据映射方式
数据映射是最常用的一种方式。准备好需要处理的数据类,直接把数据类映射到 MongoDB,并对数据集进行 CRUD 操作。
MongoDB 数据集中存放的数据,称之为文档(Document)。每个文档在存放时,都需要有一个ID,而这个 ID 的名称,固定叫 _id,类型是 MongoDB.Bson.ObjectId。
当建立映射时,如果给出 _id 字段,则 MongoDB 会采用这个 ID 做为这个文档的 ID ,如果不给出,MongoDB 会自动添加一个 _id 字段。在使用上是完全一样的。唯一的区别是,如果映射类中不写 _id,则 MongoDB 自动添加 _id 时,会用 ObjectId 作为这个字段的数据类型。
ObjectId 是一个全局唯一的数据。
MongoDB 允许使用其它类型的数据作为 ID,例如:string,int,long,GUID 等,但这就需要你自己去保证这些数据不超限并且唯一。
可以在类中修改 _id 名称为别的名称,但需要加一个描述属性 BsonId,BsonId 属性会告诉映射,topic_id 就是这个文档数据的ID 。MongoDB在保存时,会将这个 topic_id 转成 _id 保存到数据集中。
1 | public class CollectionModel |
注:在 MongoDB 数据集中,ID 字段的名称固定叫 _id。为了代码的阅读方便,可以在类中改为别的名称,但这不会影响 MongoDB 中存放的 ID 名称。
MongoDB 在早期,是不支持 Decimal 的。直到 MongoDB v3.4 开始,数据库才正式支持 Decimal。
所以,如果使用的是 v3.4 以后的版本,可以直接使用,而如果是以前的版本,需要用以下的方式:
1 | [] |
其实就是把 Decimal 通过映射,转为 Double 存储。
添加两个类 Contact 和 Author:
1 | public class Contact |
文档结构:
1 | { |
创建一个枚举 TagEnumeration:
1 | public enum TagEnumeration |
加到 CollectionModel 中:
1 | public class CollectionModel |
Demo代码:
1 | private static async Task Demo() |
保存后的文档:注意,tag 保存了枚举的值。
1 | { |
可以保存枚举的字符串。只要在 CollectionModel 中,tag 声明上加个属性:
1 | [] |
数据会变成:
1 | { |
CollectionModel 中增加一个时间字段:
1 | public DateTime post_time { get; set; } |
MongoDB 的 datetime 存储的是 unixtimestamp ,所以默认只能是 utc0 时区的,它问题出在 C# 的 DateTime 对时区的处理上遗留的问题,可以换成 DateTimeOffset。
如果只是保存(像上边这样),或者查询时使用时间作为条件(例如查询 post_time < DateTime.Now 的数据)时,是可以使用的,不会出现问题。
但是,如果是查询结果中有时间字段,那这个字段,会被 DateTime 默认设置为 DateTimeKind.Unspecified 类型。而这个类型,是无时区信息的,输出显示时,会造成混乱。
为了避免这种情况,在进行时间字段的映射时,需要加上属性:
1 | [] |
这样做,会强制 DateTime 类型的字段为 DateTimeKind.Local 类型。这时候,从显示到使用就正确了。
数据集中存放的是 UTC 时间,跟我们正常的时间有8小时时差,如果我们需要按日统计,比方每天的销售额/点击量。
按年月日时分秒拆开存放
1 | class Post_Time |
MyDateTimeSerializer
1 | public class MyDateTimeSerializer : DateTimeSerializer |
注意:使用这个方法,一定不要添加时间的属性 [BsonDateTimeOptions(Kind = DateTimeKind.Local)]
对某个特定映射的特定字段使用,比方只对 CollectionModel 的 post_time 字段来使用,可以这么写:
1 | [] |
数据声明很简单:
public Dictionary<string, int> extra_info { get; set; }
MongoDB 定义了三种保存属性:Document、ArrayOfDocuments、ArrayOfArrays,默认是 Document。
属性写法是这样的:
1 | [] |
这三种属性下,保存在数据集中的数据结构有区别。多数情况用 DictionaryRepresentation.ArrayOfDocuments。
1 | // DictionaryRepresentation.Document: |
这三种方式,从数据保存上并没有什么区别,但从查询来讲,如果这个字段需要进行查询,那三种方式区别很大。
如果采用 BsonDocument 方式查询,DictionaryRepresentation.Document 无疑是写着最方便的。
如果用 Builder 方式查询,DictionaryRepresentation.ArrayOfDocuments 是最容易写的。
DictionaryRepresentation.ArrayOfArrays 就算了。数组套数组,查询条件写死人。
用来改数据集中的字段名称。
1 | [] |
在不加 BsonElement 的情况下,通过数据映射写到数据集中的文档,字段名就是变量名,上面这个例子,字段名就是 post_time 。
加上 BsonElement 后,数据集中的字段名会变为 pt。
设置字段的默认值。
当写入的时候,如果映射中不传入值,则数据库会把这个默认值存到数据集中。
1 | [] |
用来在映射类中的数据类型和数据集中的数据类型做转换。
1 | [] |
表示,在映射类中,favor 字段是 int 类型的,而存到数据集中,会保存为 string 类型。
前边 Decimal 转换和枚举转换,就是用的这个属性。
用来忽略某些字段。
忽略的意思是:映射类中某些字段,不希望被保存到数据集中。
1 | [] |
这样,在保存数据时,字段 ignore_string 就不会被保存到数据集中。
参考:
默认是没有 categories 和 tags 的:
1 | hexo new page "tags" |
编辑 /tags/index.md
添加:
1 | type: tags |
/categories/index.md
添加:
1 | type: categories |
linux系统文件通常在 /var/log
1 | # 系统启动后的信息和错误日志 |
1 | # 查看重启的命令 |
1 | # 查看所有重启日志信息 |
参考:
ObjectId 是一个12字节 BSON 类型数据,有以下格式:
MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象。
在一个集合里面,每个文档都有唯一的 _id 值,来确保集合里面每个文档都能被唯一标识。
MongoDB 采用 ObjectId,而不是其他比较常规的做法(比如自动增加的主键)的主要原因,因为在多个服务器上同步自动增加主键值既费力还费时。
1 | # 1.创建新的ObjectId |
MongoDB 中的关系分为:嵌入式关系 和 引用式关系。
1 | { |
查询:
db.users.findOne({"name":"test"},{"address":1})
这种数据结构的缺点是,如果用户和用户地址在不断增加,数据量不断变大,会影响读写性能。
1 | { |
查询:
1 | var result = db.users.findOne({"name":"test"},{"address_ids":1}) |
注意:find 返回的数据类型是数组,findOne 返回的数据类型是对象。
MongoDB 引用有两种:
1 | # $ref:集合名称 |
实例:
1 | { |
查询:
1 | var user = db.users.findOne({"name":"test1"}) |
官方的 MongoDB 的文档中说明,覆盖查询是以下的查询:
由于所有出现在查询中的字段是索引的一部分, MongoDB 无需在整个数据文档中检索匹配查询条件和返回使用相同索引的查询结果。
因为索引存在于 RAM 中,从索引中获取数据比通过扫描文档读取数据要快得多。
实例:
1 | { |
在 users 集合中创建联合索引,字段为 gender 和 user_name :
db.users.createIndex({gender:1,user_name:1})
该索引会覆盖以下查询:
db.users.find({gender:"M"},{user_name:1,_id:0})
上述查询,MongoDB 的不会去数据库文件中查找。它会从索引中提取数据,这是非常快速的数据查询。
由于索引中不包括 _id 字段,_id 在查询中会默认返回,我们可以在 MongoDB 的查询结果集中排除它。
下面的实例没有排除 _id,查询就不会被覆盖:
db.users.find({gender:"M"},{user_name:1})
最后,如果是以下的查询,不能使用覆盖索引查询:
MongoDB 查询分析常用函数有:explain() 和 hint()。
explain 操作提供了查询信息,使用索引及查询统计等。有利于我们对索引的优化。
1 | # users 集合中创建 gender 和 user_name 的索引: |
explain() 查询返回:
1 | { |
结果集的字段:
MongoDB 中索引存储在B树结构中,所以这是也使用了 BtreeCursor 类型的游标。如果没有使用索引,游标的类型是 BasicCursor。这个键还会给出你所使用的索引的名称,你通过这个名称可以查看当前数据库下的 system.indexes 集合(系统自动创建,由于存储索引信息,这个稍微会提到)来得到索引的详细信息。hint() 来强制 MongoDB 使用一个指定的索引。
1 | db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}) |
MongoDB 提供了许多原子操作,比如文档的保存,修改,删除等,都是原子操作。
所谓原子操作就是要么这个文档保存到 MongoDB,要么没有保存到 MongoDB,不会出现查询到的文档没有保存完整的情况。
db.collection.findAndModify() 方法来判断书籍是否可结算并更新新的结算信息。
1 | db.books.findAndModify ( { |
$set
用来指定一个键并更新键值,若键不存在并创建。
{ $set : { field : value } }
$unset
用来删除一个键。
{ $unset : { field : 1} }
$inc
$inc可以对文档的某个值为数字型(只能为满足要求的数字)的键进行增减的操作。
{ $inc : { field : value } }
$push
把value追加到field里面去,field一定要是数组类型才行,如果field不存在,会新增一个数组类型加进去。
{ $push : { field : value } }
$pushAll
同 $push,只是一次可以追加多个值到一个数组字段内。
{ $pushAll : { field : value_array } }
$pull
从数组field内删除一个等于value值。
{ $pull : { field : _value } }
$addToSet
增加一个值到数组内,而且只有当这个值不在数组内才增加。
$pop
删除数组的第一个或最后一个元素
{ $pop : { field : 1 } }
$rename
修改字段名称
{ $rename : { old_field_name : new_field_name } }
$bit
位操作,integer类型
{$bit : { field : {and : 5}}}
偏移操作符
1 | t.find() { "_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"), "title" : "ABC", "comments" : [ { "by" : "joe", "votes" : 3 }, { "by" : "jane", "votes" : 7 } ] } |
实例 文档集合(users)包含了 address 子文档和 tags 数组:
1 | { |
在数组中创建索引,需要对数组中的每个字段依次建立索引。所以在我们为数组 tags 创建索引时,会为 music、cricket、blogs 三个值建立单独的索引。
1 | # 创建数组索引: |
1 | # 为子文档的三个字段创建索引,命令如下: |
额外开销
每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作。所以,如果你很少对集合进行读取操作,建议不使用索引。
内存(RAM)使用
由于索引是存储在内存( RAM )中,你应该确保该索引的大小不超过内存的限制。
如果索引的大小大于内存的限制,MongoDB 会删除一些索引,这将导致性能下降。
查询限制
索引不能被以下的查询使用:
正则表达式及非操作符,如 $nin, $not, 等。
算术运算符,如 $mod, 等。$where 子句
所以,检测你的语句是否使用索引是一个好的习惯,可以用 explain 来查看。
索引键限制
从2.6版本开始,如果现有的索引字段的值超过索引键的限制,MongoDB 中不会创建索引。
插入文档超过索引键限制
如果文档的索引字段值超过了索引键的限制,MongoDB 不会将任何文档转换成索引的集合。与 mongorestore 和 mongoimport 工具类似。
最大范围
集合中索引不能超过64个
索引名的长度不能超过128个字符
一个复合索引最多可以有31个字段
Map-Reduce 是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB 提供的 Map-Reduce 非常灵活,对于大规模数据分析也相当实用。
MapReduce 命令基本语法
1 | db.collection.mapReduce( |
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
map :映射函数 (生成键值对序列,作为 reduce 函数参数)。reduce 统计函数,reduce 函数的任务就是将 key-values 变成 key-value ,也就是把 values 数组变成一个单一的值 value。。out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。query 一个筛选条件,只有满足条件的文档才会调用 map 函数。( query,limit,sort可以随意组合)sort 和 limit 结合的 sort 排序参数(也是在发往 map 函数前给文档排序),可以优化分组机制limit 发往 map 函数的文档数量的上限(要是没有 limit,单独使用 sort 的用处不大)以下实例在集合 orders 中查找 status:"A" 的数据,并根据 cust_id 来分组,并计算 amount 的总和。

使用MapReduce
在 posts 集合中使用 mapReduce 函数来选取已发布的文章(status:”active”),并通过 user_name 分组,计算每个用户的文章数:
1 | db.posts.mapReduce( |
全文检索对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。MongoDB 从 2.4 版本开始支持全文检索,MongoDB 从3.2 版本以后添加了对中文索引的支持。
启用全文检索
MongoDB 在 2.6 版本以后是默认开启全文检索的,如果你使用之前的版本,你需要使用以下代码来启用全文检索:
1 | db.adminCommand({setParameter:true,textSearchEnabled:true}) |
创建全文索引
实例:posts 集合的文档数据,包含了文章内容(post_text)及标签(tags):
1 | { |
对 post_text 字段建立全文索引,这样我们可以搜索文章内的内容:
db.posts.createIndex({post_text:"text"})
使用全文索引
1 | db.posts.find({$text:{$search:"runoob"}}) |
旧版本的 MongoDB,可以使用以下命令:
db.posts.runCommand("text",{search:"runoob"})
使用全文索引可以提高搜索效率。
删除全文索引
1 | # 删除已存在的全文索引,可以使用 find 命令查找索引名: |
1 | # 创建物理卷 |
xfs 相关:
1 | xfs_admin: 调整 xfs 文件系统的各种参数 |
resize2fs 相关
此命令的适用范围:RedHat、RHEL、Ubuntu、CentOS、SUSE、openSUSE、Fedora。
调整 ext2\ext3\ext4 文件系统的大小,它可以放大或者缩小没有挂载的文件系统的大小。如果文件系统已经挂载,它可以扩大文件系统的大小,前提是内核支持在线调整大小。
size 参数指定所请求的文件系统的新大小。如果没有指定任何单元,那么 size 参数的单位应该是文件系统的文件系统块大小。size 参数可以由下列单位编号之一后缀:s、K、M 或 G,分别用于512字节扇区、千字节、兆字节或千兆字节。文件系统的大小可能永远不会大于分区的大小。如果未指定 Size 参数,则它将默认为分区的大小。
resize2fs 程序不操作分区的大小。如果希望扩大文件系统,必须首先确保可以扩展基础分区的大小。如果您使用逻辑卷管理器 LVM(8) ,可以使用 fdisk(8) 删除分区并以更大的大小重新创建它,或者使用 lvexport(8) 。在重新创建分区时,请确保使用与以前相同的启动磁盘圆柱来创建分区!否则,调整大小操作肯定无法工作,您可能会丢失整个文件系统。运行 fdisk(8) 后,运行 resize2fs 来调整 ext 2文件系统的大小,以使用新扩大的分区中的所有空间。
如果希望缩小 ext2 分区,请首先使用 resize2fs 缩小文件系统的大小。然后可以使用 fdisk(8) 缩小分区的大小。缩小分区大小时,请确保不使其小于 ext2 文件系统的新大小。
1 | # 语法相关 |
resize2fs 程序将启发式地确定在创建文件系统时指定的 RAID 步长。此选项允许用户显式地指定 RAID 步长设置,以便由 resize2fs 代替。
1 | # 查看防火状态 |
标准 URI 连接语法:
1 | mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]] |
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登录这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登录指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用 /database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
标准的连接格式包含了多个选项(options):
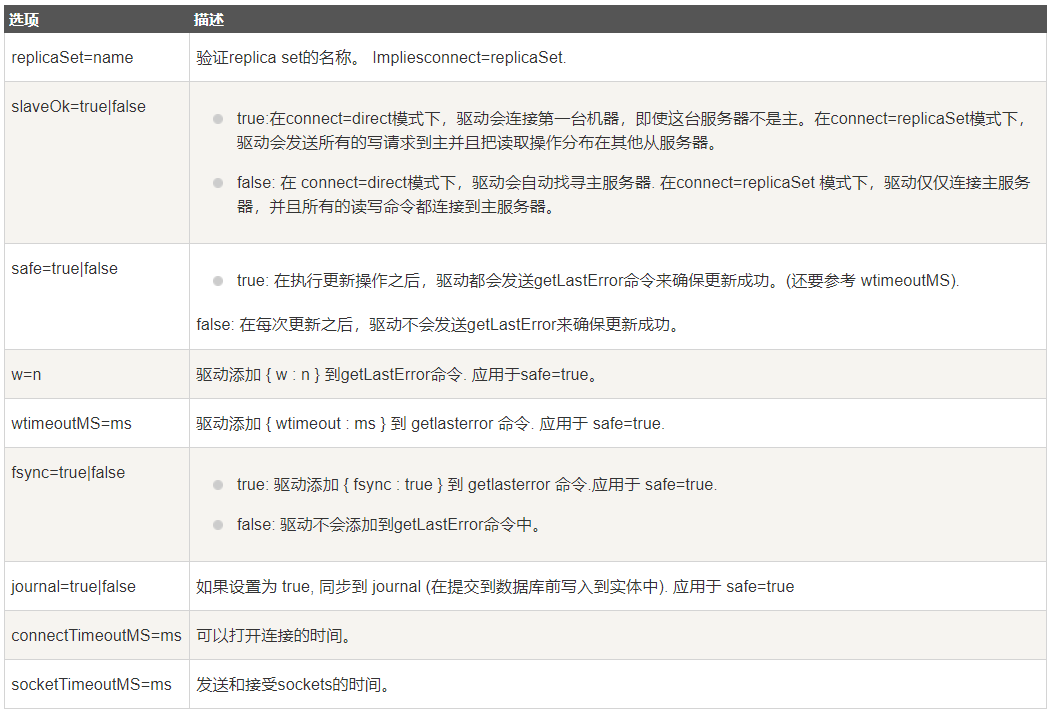
语法格式
MongoDB 创建数据库的语法格式如下:
1 | use DATABASE_NAME |
实例
1 | > use test1 |
如果数据库不存在,则创建数据库,否则切换到指定数据库。
ongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
语法格式
MongoDB 删除数据库的语法格式如下:
1 | db.dropDatabase() |
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
实例
1 | > use test1 |
语法格式
1 | db.createCollection(name, options) |
参数说明:
options 可以是如下参数

在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
可以使用 show collections 或 show tables 命令查看已有集合。
语法格式:
1 | db.collection.drop() |
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
1 | > db.createCollection("test1") |
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
1 | # 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。 |
3.2 版本之后新增insertOne,insertMany
1 | # 参数说明: |
语法格式
1 | db.collection.update( |
参数说明:
实例
1 | db.test1.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}) |
save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入。
语法格式如下:
1 | db.collection.save( |
参数说明:
在3.2版本开始,MongoDB提供以下更新集合文档的方法:
1 | # 向指定集合更新单个文档 |
MongoDB 最早删除文档使用的是 remove() 方法,后来官方把它移除了因为 remove() 并不会真正释放空间。需要继续执行 db.repairDatabase() 来回收磁盘空间。
建议在执行删除文档函数前先执行 find() 命令来判断执行的条件是否正确 db.test1.find() 。
1 | db.repairDatabase() |
官方推荐使用 deleteOne() 和 deleteMany() 方法。
语法
deleteOne() 语法:
1 | db.collection.deleteOne( |
deleteMany() 语法:
1 | db.collection.deleteMany( |
1 | # 删除集合下全部文档 |
MongoDB 查询文档使用 find(), findOne() 方法。
find() 方法以非结构化的方式来显示所有文档。
语法格式
db.collection.find(query, projection)
1 | # projection入参格式为{columnA : 0/1,columnB : 0/1} |
如:{title:1},表示查询出的每条记录中只显示 title 字段内容。{description:0},表示查询出的每条记录中不显示 description 字段内容(其他字段都展示)。
注:_id(主键)字段默认为 1,可指定 {_id:0} 来不输出 _id 字段值。
指定 projection 格式如下,有两种模式
1 | db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键 |
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
1 | db.collection.find(query, {title: 1, by: 0}) # 错误 |
若不想指定查询条件参数 query 可以 用 {} 代替,但是需要指定 projection 参数:
1 | querydb.collection.find({}, {title: 1}) |
AND 条件
1 | db.test1.find({key1:value1, key2:value2}).pretty() |
OR 条件
使用关键字 $or,语法格式如下:
1 | db.test1.find( |
AND 和 OR 联合使用
where likes>50 AND (by = 'test1' OR title = 'MongoDB')
1 | db.test1.find({"likes": {$gt:50}, $or: [{"by": "test1"},{"title": "MongoDB"}]}).pretty() |
模糊查询
1 | # 查询 title 包含"教"字的文档: |
结合查询语句使用。
$type 操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
获取 test1 集合中 title 为 String 的数据
1 | db.test1.find({"title" : {$type : 2}}) |
1 | # Limit() 方法 |
skip 和limit方法只适合小数据量分页,如果是百万级效率就会非常低,因为skip方法是一条条数据数过去的,建议使用 where limit。
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
1 | # 语法 |
3.0.0 版本前创建索引方法为 db.collection.ensureIndex() ,之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
语法
1 | db.collection.createIndex(keys, options) |
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引 -1 按降序来创建索引。
可选参数:

1 | # 查看集合索引 |
保存最近三个月的文档(单位秒),当中途修改了createdAt的值时,
则不会删除文档(指定的时间是字段与当前时间的差值)。
db.user.createIndex({"createdAt": 1},{expireAfterSeconds: 60*60*24*3});
若需求变动,需要将三个月修改为一个月可以使用collMod,如下:
db.runCommand({collMod: 'user', index: {keyPattern:{"createdAt": 1}, expireAfterSeconds:60*60*24*1}});
TTL索引限制:
MongoDB中聚合( aggregate )主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
aggregate() 方法
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
聚合的表达式:
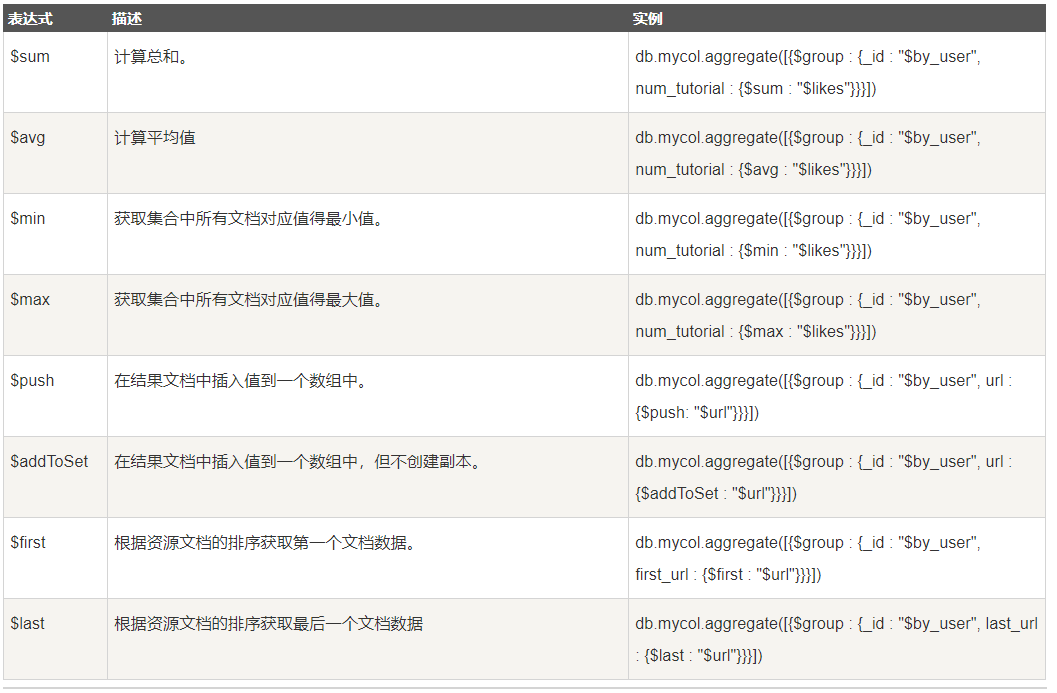
实例:
1 | db.test1.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}]) |
MongoDB 的聚合管道将 MongoDB 文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
$match 使用 MongoDB 的标准查询操作。MongoDB 聚合管道返回的文档数。注意:当 match 条件和 group 同时存在时,顺序会影响检索结果,必须先写 match 在前面。
时间关键字如下:
实例:
1 | db.getCollection('m_msg_tb').aggregate( |
参考:
utf8mb4 的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。
1 | mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%'; |
1 | # 修改database默认的字符集 |
1 | # 对本地的mysql客户端的配置 |
1 | # 必须保证一下系统变量是 utf8mb4 |
参考: