Mysql执行flush privileges报错:Table 'mysql.servers' doesn't exist
mysql执行刷新权限报错:Table 'mysql.servers' doesn't exist
1 | mysql> flush privileges; |
SQL脚本:
1 | CREATE TABLE `servers` ( |
参考:
mysql执行刷新权限报错:Table 'mysql.servers' doesn't exist
1 | mysql> flush privileges; |
SQL脚本:
1 | CREATE TABLE `servers` ( |
参考:
主从复制(也称 Replication, AB 复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
复制是异步的 从站不需要永久连接以接收来自主站的更新,从服务器甚至可以通过拨号断断续续地连接主服务器。
根据配置,可以复制数据库中的所有数据库,所选数据库甚至选定的表。
有以下几种形式:
MySQL中复制的优点:
1,横向扩展解决方案 - 在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或多个从设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显着提高了越来越多的从设备的读取速度。
2,数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
3,分析 - 可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。
4,远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
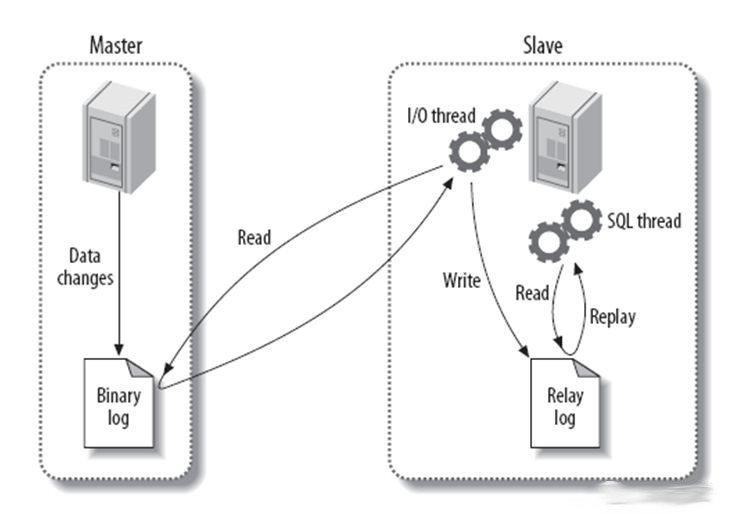
主要过程
1、主服务器MySQL服务将所有的写操作记录在 binlog 日志中,并生成 log dump 线程,将 binlog 日志传给从服务器MySQL服务的 I/O 线程。
2、从服务器MySQL服务生成两个线程,一个是 I/O 线程,另一个是 SQL 线程。
3、从库 I/O 线程去请求主库的 binlog 日志,并将 binlog 日志中的文件写入 relaylog(中继日志)中。
4、从库的 SQL 线程会读取 relaylog 中的内容,并解析成具体的操作,来实现主从的操作一致,达到最终两个数据库数据一致的目的。
注意点:
mysqld将数字扩展名附加到二进制日志基本名称以生成二进制日志文件名。每次服务器创建新日志文件时,该数字都会增加,从而创建一系列有序的文件。每次启动或刷新日志时,服务器都会在系列中创建一个新文件。服务器还会在当前日志大小达到 max_binlog_size 参数设置的大小后自动创建新的二进制日志文件 。二进制日志文件可能会比 max_binlog_size 使用大型事务时更大, 因为事务是以一个部分写入文件,而不是在文件之间分割。
为了跟踪已使用的二进制日志文件, mysqld 还创建了一个二进制日志索引文件,其中包含所有使用的二进制日志文件的名称。默认情况下,它具有与二进制日志文件相同的基本名称,并带有扩展名 .index。在 mysqld 运行时,您不应手动编辑此文件。
二进制日志文件 通常表示包含数据库事件的单个编号文件。二进制日志 表示含编号的二进制日志文件集加上索引文件。
SUPER 权限的用户可以使用 SET sql_log_bin=0 语句禁用其当前环境下自己的语句的二进制日志记录。
主从部署必要条件:
主服务器:
1、开启二进制日志
2、配置唯一的server-id
3、获得master二进制日志文件名及位置
4、创建一个用于slave和master通信的用户账号
从服务器:
1、配置唯一的server-id
2、使用master分配的用户账号读取master二进制日志
3、启用slave服务
主节点修改配置文件
1 | # 服务器唯一ID,一般取IP最后一段 |
创建日志目录,并赋予权限:
1 | mkdir /usr/local/mysql/binlogs |
重启:
/etc/init.d/mysqld restart
如果省略 server-id(或将其显式设置为默认值0),则主服务器拒绝来自从服务器的任何连接。
为了在使用带事务的 InnoDB 进行复制设置时尽可能提高持久性和一致性,
您应该在master my.cnf 文件中使用以下配置项:
1 | innodb_flush_log_at_trx_commit = 1 |
确保在主服务器上 skip_networking 选项处于 OFF 关闭状态, 这是默认值。
如果是启用的,则从站无法与主站通信,并且复制失败。
1 | mysql> show variables like '%skip_networking%'; |
从服务器配置
1 | # my.cnf 文件 |
主服务器创建用于复制数据的用户
语法:
grant 权限 on 数据库对象 to 用户
grant 权限1,权限2,…权限n on 数据库名称.表名称 to 用户名@用户地址 identified by ‘连接口令’ WITH GRANT OPTION;
示例:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
取消权限:revoke all on *.* from root@localhost;
最后执行:flush privileges;
GRANT:赋权命令
ALL PRIVILEGES:当前用户的所有权限
ON:介词
*.*:当前用户对所有数据库和表的相应操作权限
TO:介词
‘root’@’%’:权限赋给root用户,所有ip都能连接
IDENTIFIED BY ‘123456’:连接时输入密码,密码为123456
WITH GRANT OPTION:允许级联赋权,表示该用户可以将自己拥有的权限授权给别人。
1 | # 连接到mysql,输入密码 |
备份主服务器数据
使用 scp 或 rsync 等工具,把备份出来的数据传输到从服务器中。
1 | # 进入 mysql 安装目录 |
从服务器开始复制
1 | # 登录 主mysql |
设置从库只读
1 | # 查看当前只读的状态 |
复制相关命令:
1 | # 停止slave |
查看 binlog 日志
show binlog events\G
Pos~End_log_pos - 1MySQL复制功能使用三个线程实现,一个在主服务器上,两个在从服务器上:
Binlog转储线程 主设备创建一个线程,以便在从设备连接时将二进制日志内容发送到从设备。可以 SHOW PROCESSLIST 在主服务器的输出中将此线程标识为 Binlog Dump 线程。
二进制日志转储线程获取主机二进制日志上的锁,用于读取要发送到从机的每个事件。一旦读取了事件,即使在事件发送到从站之前,锁也会被释放。
从属 I/O线程 在从属服务器上发出 START SLAVE 语句时,从属服务器会创建一个 I/O 线程,该线程连接到主服务器并要求主服务器发送其在二进制日志中的更新记录。
从属 I/O 线程读取主 Binlog Dump 线程发送的更新,并将它们复制到包含从属中继日志的本地文件。
此线程的状态显示为 Slave_IO_running 输出 SHOW SLAVE STATUS 或 Slave_running 输出中的状态 SHOW STATUS 。
从属SQL线程 从属设备创建一个SQL线程来读取由从属 I/O 线程写入的中继日志,并执行其中包含的事件。
当从属服务器从放的事件,追干上主服务器的事件后,从属服务器的 I/O 线程将会处于休眠状态,直到主服务器的事件有更新时,被主服务器发送的信号唤醒。
每个 主/从 连接有三个线程。具有多个从站的主站为每个当前连接的从站创建一个二进制日志转储线程,每个从站都有自己的 I/O和SQL线程。
从站使用两个线程将读取更新与主站分开并将它们执行到独立任务中。因此,如果语句执行缓慢,则不会减慢读取语句的任务。例如,如果从服务器尚未运行一段时间,则当从服务器启动时,其 I/O 线程可以快速从主服务器获取所有二进制日志内容,即使SQL线程远远落后。如果从服务器在SQL线程执行了所有获取的语句之前停止,则 I/O 线程至少已获取所有内容,以便语句的安全副本本地存储在从属的中继日志中,准备在下次执行时执行 SLAVE开始。
主服务器上,输入 SHOW PROCESSLIST 如下所示:
1 | mysql> show processlist\G |
该线程是 Binlog Dump 为连接的从属服务的复制线程。该 State 信息表明所有未完成的更新已发送到从站,并且主站正在等待更多更新发生。如果 Binlog Dump 在主服务器上看不到任何 线程,则表示复制未运行,说明目前没有连接任何从站。
多线程复制在 5.6 中被引入,并且在 5.7 中得到了进一步的完善。5.7 中是基于逻辑时钟的方式进行的多线程复制。
1 | # 1,从库上查看默认的多线程复制类型 |
vim /usr/local/mysql/my.cnf
在 [mysqld] 下添加:
1 | slave-parallel-type=LOGICAL_CLOCK |
重启mysql
1 | /etc/init.d/mysqld restart |
验证:
1 | show variables like "slave_parallel_type"; |
参考:
下载离线包:
https://dl.min.io/server/minio/release/linux-amd64/minio
或者使用命令下载(需要接入互联网):
1 | wget https://dl.min.io/server/minio/release/linux-amd64/minio |
移动到/usr/local/minio文件夹
1 | mkdir -p /usr/local/minio/bin |
命令格式:
1 | ./minio -C \"${minio_config}\" server --address=\"${minio_address}\" ${minio_disks} |
-C:配置文件
进入到软件包所在目录:
终端启动,这种方式关闭终端,服务会停止。
1 | cd /ldjc/rj |
后台运行
1 | cd /ldjc/rj |
新建配置文件
1 | cd /usr/local/minio |
配置文件内容:
1 | MINIO_ACCESS_KEY=admin |
新建服务
在 /etc/systemd/system,新建一个 minio.service :
1 | touch /etc/systemd/system/minio.service |
参考:linux-systemd/minio.service
1 | [Unit] |
启动服务
1 | systemctl enable minio.service |
1 | #查看端口 |
详细信息请参考官网:How to secure access to MinIO server with TLS
1 | openssl genrsa -out private-pkcs8-key.key 2048 |
生成配置文件 openssl.conf
1 | [req] |
使用配置文件生成证书:
1 | openssl req -x509 -nodes -days 730 -newkey rsa:2048 -keyout private.key -out public.crt -config openssl.conf |
参考:
5.7 以及之后的版本中会遇到这样的错误:
1 | Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'name' which is not functionally dependent on columns in GROUP BY clause; |
mysql 5.7版本默认的sql配置是:sql_mode=”ONLY_FULL_GROUP_BY”,这个配置严格执行了”SQL92标准”。
查看sql_mode的语句:
1 | select @@GLOBAL.sql_mode; |
很多从5.6升级到5.7时,为了语法兼容,大部分都会选择调整sql_mode,使其保持跟5.6一致,为了尽量兼容程序。
原因分析:
再输出的结果 target list 中,即select后面跟着的字段,还有一个地方 group by column,就是 group by后面跟着的字段。由于开启了 ONLY_FULL_GROUP_BY 的设置,所以如果一个字段没有在 target list
和 group by 字段中同时出现,或者是聚合函数的值的话,那么这条sql查询是被mysql认为非法的,会报错误。
重启mysql数据库服务之后,ONLY_FULL_GROUP_BY还会出现。
1 | set @@GLOBAL.sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION |
修改 mysql 配置文件,/usr/local/mysql/my.cnf,添加如下代码,之后重启mysql服务。
1 | #主要需要添加到 [mysql] [mysqld] 标签下,加入到其他地方,即使重启后也不生效。 |
重启:
1 | /etc/init.d/mysqld restart |
参考:
5分钟学会MySQL-this is incompatible with sql_mode=only_full_group_by错误解决方案
转载:
CORS是一个W3C标准,全称是”跨域资源共享”(Cross-origin resource sharing)。
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。
CORS 与 JSONP 的使用目的相同,但是比 JSONP 更强大。
JSONP 只支持 GET 请求,CORS 支持所有类型的 HTTP 请求。JSONP 的优势在于支持老式浏览器,以及可以向不支持 CORS 的网站请求数据。
浏览器将 CORS 请求分成两类:
简单请求(simple request)和 非简单请求(not-so-simple request)。
只要同时满足以下两大条件,就属于简单请求。
1 | 2.请求方法是以下三种方法之一: |
这是为了兼容表单(form),因为历史上表单一直可以发出跨域请求。AJAX 的跨域设计就是,只要表单可以发,AJAX 就可以直接发。
凡是不同时满足上面两个条件,就属于非简单请求。
浏览器对这两种请求的处理,是不一样的。
浏览器直接发出 CORS 请求。具体来说,就是在头信息之中,增加一个 Origin 字段。
下面是一个例子,浏览器发现这次跨源 AJAX 请求是简单请求,就自动在头信息之中,添加一个Origin字段。
1 | GET /cors HTTP/1.1 |
Origin 字段用来说明,本次请求来自哪个源(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意这次请求。
如果Origin指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应。浏览器发现,这个回应的头信息没有包含 Access-Control-Allow-Origin 字段,就知道出错了,从而抛出一个错误,被 XMLHttpRequest 的onerror回调函数捕获。注意,这种错误无法通过状态码识别,因为HTTP回应的状态码有可能是200。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段,都以 Access-Control- 开头。
1 | Access-Control-Allow-Origin: http://api.bob.com |
Access-Control-Allow-Origin
该字段是必须的。它的值要么是请求时 Origin 字段的值,要么是一个*,表示接受任意域名的请求。
Access-Control-Allow-Credentials
该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。
Access-Control-Expose-Headers
该字段可选。CORS请求时,XMLHttpRequest 对象的getResponseHeader()方法只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在 Access-Control-Expose-Headers 里面指定。上面的例子指定,getResponseHeader(‘FooBar’)可以返回FooBar字段的值。
withCredentials 属性
CORS请求默认不发送Cookie和HTTP认证信息。如果要把Cookie发到服务器,一方面要服务器同意,指定
Access-Control-Allow-Credentials 字段。
1 | Access-Control-Allow-Credentials: true |
另一方面,开发者必须在AJAX请求中打开 withCredentials 属性。
1 | var xhr = new XMLHttpRequest(); |
否则,即使服务器同意发送Cookie,浏览器也不会发送。或者,服务器要求设置Cookie,浏览器也不会处理。
但是,如果省略 withCredentials 设置,有的浏览器还是会一起发送Cookie。这时,可以显式关闭 withCredentials。
1 | xhr.withCredentials = false; |
需要注意的是,如果要发送Cookie,Access-Control-Allow-Origin 就不能设为星号,必须指定明确的、与请求网页一致的域名。同时,Cookie依然遵循同源政策,只有用服务器域名设置的Cookie才会上传,其他域名的Cookie并不会上传,且(跨源)原网页代码中的document.cookie也无法读取服务器域名下的Cookie。
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是 PUT 或 DELETE ,或者 Content-Type 字段的类型是 application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为”预检”请求(preflight)。
浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的 XMLHttpRequest 请求,否则就报错。
下面是一段浏览器的JavaScript脚本。
1 | var url = 'http://api.alice.com/cors'; |
上面代码中,HTTP请求的方法是PUT,并且发送一个自定义头信息 X-Custom-Header。
浏览器发现,这是一个非简单请求,就自动发出一个”预检”请求,要求服务器确认可以这样请求。下面是这个”预检”请求的HTTP头信息。
1 | OPTIONS /cors HTTP/1.1 |
“预检”请求用的请求方法是 OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是Origin,表示请求来自哪个源。
除了 Origin 字段,”预检”请求的头信息包括两个特殊字段。
Access-Control-Request-Method
该字段是必须的,用来列出浏览器的 CORS 请求会用到哪些HTTP方法,上例是PUT。
Access-Control-Request-Headers
该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段,上例是 X-Custom-Header 。
服务器收到”预检”请求以后,检查了 Origin、Access-Control-Request-Method 和 Access-Control-Request-Headers 字段以后,确认允许跨源请求,就可以做出回应。
1 | HTTP/1.1 200 OK |
上面的HTTP回应中,关键的是 Access-Control-Allow-Origin 字段,表示 http://api.bob.com 可以请求数据。该字段也可以设为星号,表示同意任意跨源请求。
1 | Access-Control-Allow-Origin: * |
如果服务器否定了”预检”请求,会返回一个正常的HTTP回应,但是没有任何 CORS 相关的头信息字段。这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被 XMLHttpRequest 对象的 onerror 回调函数捕获。控制台会打印出如下的报错信息。
1 | XMLHttpRequest cannot load http://api.alice.com. |
服务器回应的其他 CORS 相关字段如下。
1 | Access-Control-Allow-Methods: GET, POST, PUT |
Access-Control-Allow-Methods
该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法。注意,返回的是所有支持的方法,而不单是浏览器请求的那个方法。这是为了避免多次”预检”请求。
Access-Control-Allow-Headers
如果浏览器请求包括 Access-Control-Request-Headers 字段,则 Access-Control-Allow-Headers 字段是必需的。它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段,不限于浏览器在”预检”中请求的字段。
Access-Control-Allow-Credentials
该字段与简单请求时的含义相同。
Access-Control-Max-Age
该字段可选,用来指定本次预检请求的有效期,单位为秒。上面结果中,有效期是20天(1728000秒),即允许缓存该条回应1728000秒(即20天),在此期间,不用发出另一条预检请求。
一旦服务器通过了”预检”请求,以后每次浏览器正常的CORS请求,就都跟简单请求一样,会有一个 Origin 头信息字段。服务器的回应,也都会有一个 Access-Control-Allow-Origin 头信息字段。
下面是”预检”请求之后,浏览器的正常CORS请求。
1 | PUT /cors HTTP/1.1 |
上面头信息的Origin字段是浏览器自动添加的。
下面是服务器正常的回应。
1 | Access-Control-Allow-Origin: http://api.bob.com |
上面头信息中,Access-Control-Allow-Origin 字段是每次回应都必定包含的。
Linux crontab是用来定期执行程序的命令。
当安装完成操作系统之后,默认便会启动此任务调度命令。
注意:新创建的 cron 任务,不会马上执行,至少要过 2 分钟后才可以,当然你可以重启 cron 来马上执行。
crontab命令用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于 /etc/crontab 文件中,以供之后读取和执行。
cron 系统调度进程。 可以使用它在每天的非高峰负荷时间段运行作业,或在一周或一月中的不同时段运行。cron是系统主要的调度进程,可以在无需人工干预的情况下运行作业。crontab命令允许用户提交、编辑或删除相应的作业。每一个用户都可以有一个crontab文件来保存调度信息。
linux 任务调度的工作主要分为以下两类:
1、系统执行的工作:系统周期性所要执行的工作,如备份系统数据、清理缓存
2、个人执行的工作:某个用户定期要做的工作,例如每隔10分钟检查邮件服务器是否有新信,这些工作可由每个用户自行设置
crontab命令是 cron table 的简写,它是 cron 的配置文件,也可以叫它作业列表,我们可以在以下文件夹内找到相关配置文件。
/var/spool/cron/ 目录下存放的是每个用户包括root的crontab任务,每个任务以创建者的名字命名/etc/crontab 这个文件负责调度各种管理和维护任务。/etc/cron.d/ 这个目录用来存放任何要执行的crontab文件或脚本。
/etc/crontab
1 | more /etc/crontab |
/var/spool/cron
每个用户都会生成一个自动生成一个自己的 crontab 文件,一般位于 /var/spool/cron 目录下
1 | cd /var/spool/cron |
如果你用命令 crontab -r 就会删除当前用户的crontab文件,例如你切换到oracle账号下,执行了该命令,那么 /var/spool/cron/oracle 文件就会删除,如果要创建该文件只需要用 crontab -e 命令即可。注意,普通用户一般没有权限访问 /var/spool/cron
我们还可以把脚本放在 /etc/cron.hourly、/etc/cron.daily、/etc/cron.weekly、/etc/cron.monthly 目录中,让它每小时/天/星期、月执行一次。
系统管理员可以通过 cron.deny 和 cron.allow 这两个文件来禁止或允许用户拥有自己的crontab文件。
/etc/cron.deny 表示不能使用 crontab 命令的用户
/etc/cron.allow 表示能使用 crontab 的用户。
默认情况下,cron.allow 文件不存在。如果两个文件同时存在,那么 /etc/cron.allow 优先。如果两个文件都不存在,那么只有超级用户可以安排作业。
ls -lrt cron*
1 | ls -lrt cron* |
注意:不同版本的Linux系统,可能crontab手册内容有所出入,请以实际版本为准。
1 | man crontab | more |
配置定时任务时,需要注意两个问题:
1: 在SHELL中设置了必要的环境变量;例如一个shell脚本手工执行OK,但是配置成后台作业执行时,获取不到ORACLE的环境变量,这是因为crontab环境变量问题,Crontab的环境默认情况下并不包含系统中当前用户的环境。所以,你需要在shell脚本中添加必要的环境变量的设置
2: 尽量所有的文件都采用完全路径方式,避免使用相对路径。
参考:
Linux logrotate 命令用于管理记录文件。
使用 logrotate 指令,可让你轻松管理系统所产生的记录文件。它提供自动替换,压缩,删除和邮寄记录文件,每个记录文件都可被设置成每日,每周或每月处理,也能在文件太大时立即处理。例如,你可以设置 logrotate,让 /var/log/foo 日志文件每30天轮循,并删除超过6个月的日志。配置完后,logrotate 的运作完全自动化,不必进行任何进一步的人为干预。
logrotate 需要的 cron 任务应该在安装时就自动创建好了,下面代码以centos7.4为例:
1 | cat /etc/cron.daily/logrotate |
Linux系统自带的日志滚动工具 logrotate 由两部分组成:
一是命令行工具 logrotate;
二是后台服务 rsyslogd。
使用 rsyslogd ,只需简单的配置即可实现日志滚动。rsyslogd 的配置文件为 /etc/logrotate.conf,但一般不建议直接修改 logrotate.conf ,而是在目录 /etc/logrotate.d 下新增文件的方式。logrotate.conf 会 include 所有 logrotate.d 目录下的文件,
语法是一致的,区别是 logrotate.conf 定义了默认的配置,而 logrotate.d 目录下为专有配置。
截至到 redis-5.0 版本,redis 仍然不会自动滚动日志文件,如果不处理则日志文件日积月累越来越大,最终将导致磁盘满告警,
使用命令查看磁盘使用情况:
1 | ls -lh |
下列为redis的配置示例:
1 | # cat /etc/logrotate.d/redis |
注:postrotate/endscript 可以去掉,即:
1 | # cat /etc/logrotate.d/redis |
配置项说明:
可以使用 man logrotate 命令查看详情。
monthly: 日志文件将按月轮循。其它可用值为 daily,weekly 或者 yearly。rotate 指定日志文件备份数,一次将存储5个归档日志。对于第六个归档,时间最久的归档将被删除,如果值为0表示不备份minsize 表示日志文件达到多大才滚动nocompress 表示是否压缩备份的日志文件,取值:compress,nocompressdelaycompress: 总是与 compress 选项一起用,delaycompress 选项指示 logrotate 不要将最近的归档压缩,压缩将在下一次轮循周期进行。这在你或任何软件仍然需要读取最新归档时很有用。missingok 在日志轮循期间,任何错误将被忽略notifempty 日志文件为空时,不进行轮转,默认值为 ifemptycreate 以指定的权限创建全新的日志文件,同时logrotate也会重命名原始日志文件。logrotate 是以 root 运行的,如果目标日志文件非root运行,则这个一定要指定好。postrotate/endscript: 在所有其它指令完成后,postrotate 和 endscript 里面指定的命令将被执行。在这种情况下,rsyslogd 进程将立即再次读取其配置并继续运行。dateext:就是切割后的日志文件以当前日期为格式结尾,如 xxx.log-20201016 这样,如果注释掉,切割出来是按数字递增,即前面说的 xxx.log-1这种格式。注意,修改后需要重启下 rsyslogd。如果是 CentOS 可使用下列任意一种方式重启
(实际上 systemctl 新方式,而 service 实际也是使用 systemctl ):
1 | service rsyslog restart |
创建测试日志文件
1 | # 创建文件 |
logrotate 可以在任何时候从命令行手动调用。
要调用为 /etc/lograte.d/ 下配置的所有日志调用 logrotate :
logrotate /etc/logrotate.conf
要为某个特定的配置调用 logrotate :
logrotate /etc/logrotate.d/log-file
logrotate参数说明
1 | # -d 选项以预演方式运行logrotate |
参考:
先用 chmod 让Shell脚本有可执行权限,Linux下面用命令如何运行Shell脚本的方法,有两种方法:
1 | # 1, ./ 加上文件名 .sh |
如果没有权限,需要先设置权限,命令如下:
1 | # 添加执行权限 |
参考:
什么是 Transparent Huge Pages?为提升性能,通过大内存页来替代传统的4K页,使用得管理虚拟地址数变少,加快从虚拟地址到物理地址的映射,以及摒弃内存页面的换入换出以提高内存的整体性能。内核 Kernel 将程序缓存内存中,每页内存以2M为单位。相应的系统进程为 khugepaged。
在Linux中,有两种方式使用 Huge Pages,一种是2.6内核引入的 HugeTLBFS,另一种是2.6.36内核引入的THP。HugeTLBFS 主要用于数据库,THP广泛应用于应用程序。
一般可以在 rc.local 或 /etc/default/grub 中对 Huge Pages 进行设置。
Linux下的大页分为两种类型:标准大页(Huge Pages)和透明大页(Transparent Huge Pages)。Huge Pages有时候也翻译成大页/标准大页/传统大页,它们都是Huge Pages的不同中文翻译名而已。目的是使用更大的内存页面(memory page size) 以适应越来越大的系统内存,让操作系统可以支持现代硬件架构的大页面容量功能。透明大页(Transparent Huge Pages)缩写为THP,这个是RHEL 6(其它分支版本SUSE Linux Enterprise Server 11, and Oracle Linux 6 with earlier releases of Oracle Linux Unbreakable Enterprise Kernel 2 (UEK2))开始引入的一个功能。具体可以参考官方文档。这两者的区别在于大页的分配机制,标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式。
自CentOS6版本开始引入了Transparent Huge Pages(THP),从 CentOS7 版本开始,该特性默认就会启用。尽管THP的本意是为提升内存的性能,不过某些数据库厂商还是建议直接关闭THP(比如说 ORACLE、MariaDB、MongoDB 等),否则可能会导致性能出现下降。
首先检查THP的启用状态:
1 | [root@localhost ~]# cat /sys/kernel/mm/transparent_hugepage/defrag |
这个状态就说明都是启用的。
我们这个时候当然可以逐个修改上述两文件,来禁用THP,但要想一劳永逸的令其永久生效,还是参考下列的步骤。
编辑 rc.local 文件:
1 | [root@localhost ~]# vim /etc/rc.local |
增加下列内容:
1 | if test -f /sys/kernel/mm/transparent_hugepage/enabled; then |
保存退出,然后赋予 rc.local 文件执行权限:
1 | [root@localhost ~]# chmod +x /etc/rc.local |
最后重启系统,以后再检查THP应该就是被禁用了
1 | [root@localhost ~]# cat /sys/kernel/mm/transparent_hugepage/enabled |
参考:
Linux传统Huge Pages与Transparent Huge Pages再次学习总结
OOM,全称 Out-Of-Memory,是一种内存分配策略。
所谓overcommit就是操作系统分配给进程的总内存大小超过了实际可用的内存,对进程而言实为虚拟内存,一个进程占用的虚拟内存空间通常比物理空间要大,甚至可能大许多,这样做的原因是进程实际上使用的内存往往比申请的内存要少。比如有个进程申请了1G的内存,但实际上它只在一小段时间里加载了大量数据,需要使用较大的内存,而在运行过程的其他大部分时间里只用了100M的内存。这样其实有900多M的内存在大部分时间里是闲置的,完全可以分给其他进程,overcommit的机制就能充分利用这些闲置的内存。
内核参数 overcommit_memory,
可选值:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
有三种方式修改内核参数,但要有root权限:
(1)编辑 /etc/sysctl.conf ,改 vm.overcommit_memory=1 ,然后 sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
(3)echo 1 > /proc/sys/vm/overcommit_memory
系统是否行使OOM,由 /proc/sys/vm/panic_on_oom 的值决定,当 /proc/sys/vm/panic_on_oom 取值为1时表示关闭OOM,取值0时表示启用OOM。
Linux对大部分申请内存的请求都回复”yes”,以便能跑更多更大的程序。因为申请内存后,并不会马上使用内存。
Linux内核为了提高内存的使用效率采用过度分配内存(over-commit memory)的办法,造成物理内存过度紧张进而触发OOM killer机制来杀死一些进程(用户态进程,不是内核线程)回收内存。
该机制会监控那些占用内存过大,尤其是瞬间很快消耗大量内存的进程,为了防止内存耗尽会把该进程杀掉。
Linux在内存分配路径上会对内存余量做检查:
(1)如果检查到内存不足,则触发OOM机制。
(2)OOM首先会对系统所有进程(出init和内核线程等特殊进程)进行打分,并选出最bad的进程;然后杀死该进程。
(3)同时会触发内核oom_reaper进行内存收割。
(4)同时内核还提供了sysfs接口系统OOM行为,以及进程OOM行为。
Linux下每个进程都有自己的OOM权重,在 /proc/<pid>/oom_adj 里面,范围是-17到+15,取值越高,越容易被杀掉。
如果将 /proc/sys/vm/oom_kill_allocating_task 的值设置为1,则OOM时直接KILL当前正在申请内存的进程,否则OOM根据进程的oom_adj和oom_score来决定。
/proc/xxx/oom_adj:表示进程被 OOM KILLER 杀死的权重,可读写,范围是-17~15。值越大被KILL的概率越高,当进程的oom_adj值为-17时,表示永远不会被OOM KILLER选中。
/proc/xxx/oom_score_adj,可读写,范围是-1000~1000。
什么是Overcommit?当已申请的内存(Committed_AS)大小超出CommitLimit值时即为Overcommit,执行命令 cat /proc/meminfo |grep CommitLimit 可查看CommitLimit的当前大小。
CommitLimit为系统当前可以申请的内存总大小,即内存分配上限,当 overcommit_memory 值为2时,其值等于:SwapTotal + MemTotal * overcommit_ratio。
而Committed_AS,表示所有进程已申请的内存总和。命令 sar -r 输出中的 kbcommit 对应 /proc/meminfo 中的 Committed_AS ,而 %commit 值等于 Committed_AS/(MemTotal+SwapTotal) 。
如果是大内存机器,可以考虑适当调大 /proc/sys/vm/min_free_kbytes 的值,但不能太大了,不然容易频繁触发内存回收,min_free_kbytes 是内核保留空闲内存最小值,作用是保障必要时有足够内存使用。
参考:
linux的vm.overcommit_memory的内存分配参数详解