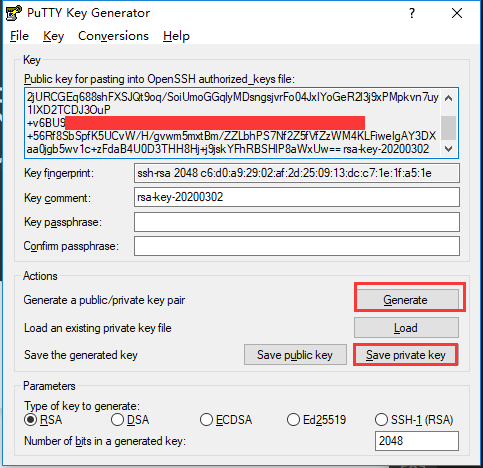
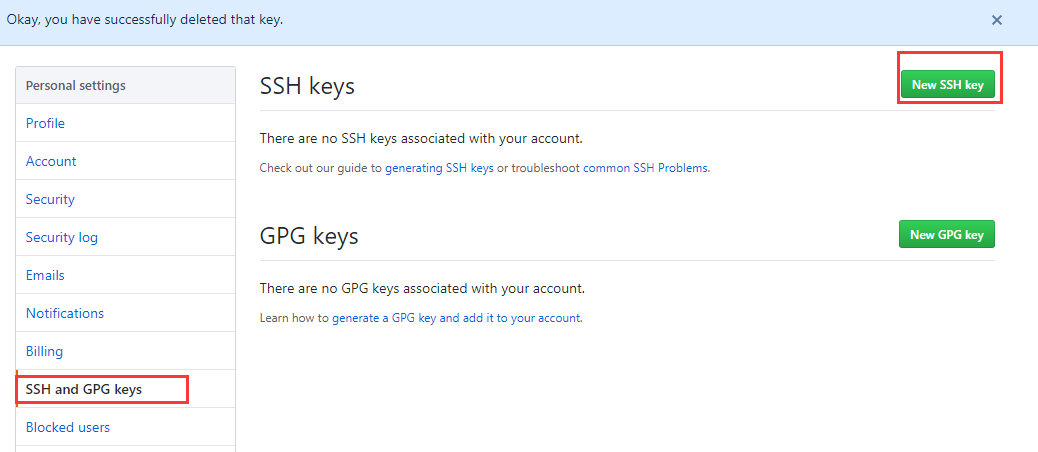
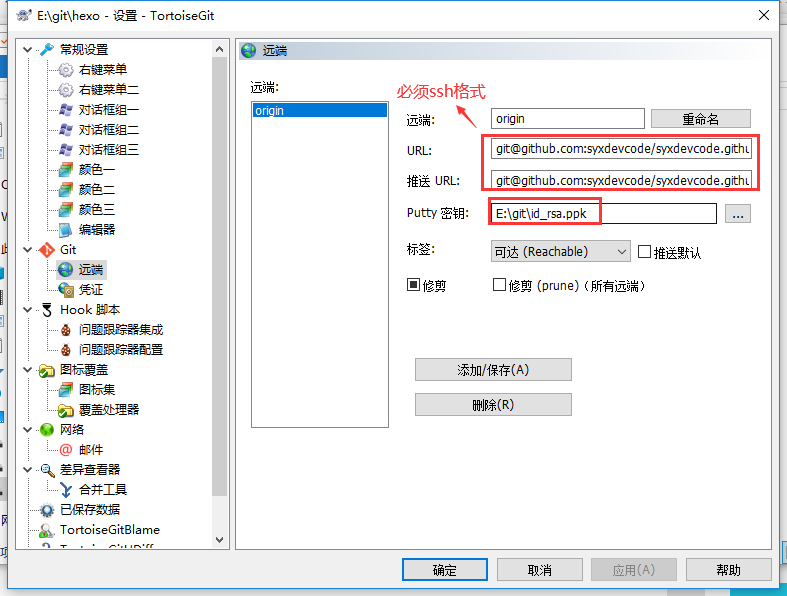
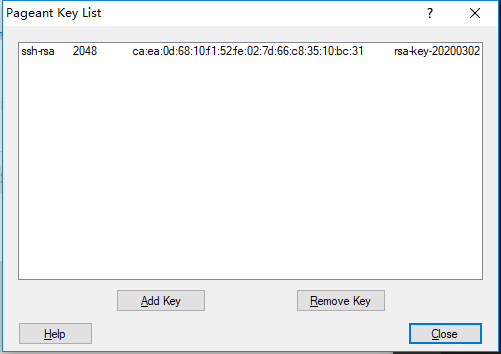
win10安装linux子系统
简介
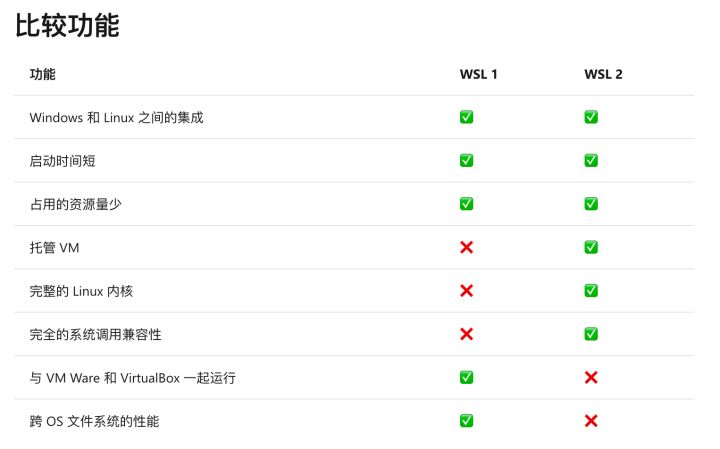
WSL1 和 WSL2
相比于 WSL1,WSL2 通过虚拟机的方式带来了更完整的 Linux 内核,但这种方式也引入了一些问题,微软给出了下面的图表来展示这些不同:
安装
1 | # 完全未安装 WSL 时才有效 |
--install 命令执行以下操作:
- 启用可选的 WSL 和虚拟机平台组件
- 下载并安装最新 Linux 内核
- 将 WSL 2 设置为默认值
- 下载并安装 Ubuntu Linux 发行版(可能需要重新启动)
IHostedService后台任务摘要
后台任务
摘自:Background tasks with hosted services in ASP.NET Core
BackgroundService is a base class for implementing a long running IHostedService.
ExecuteAsync(CancellationToken) is called to run the background service. The implementation returns a Task that represents the entire lifetime of the background service. No further services are started until ExecuteAsync becomes asynchronous, such as by calling . Avoid performing long, blocking initialization work in . The host blocks in StopAsync(CancellationToken) waiting for to complete.awaitExecuteAsyncExecuteAsync
The cancellation token is triggered when IHostedService.StopAsync is called. Your implementation of should finish promptly when the cancellation token is fired in order to gracefully shut down the service. Otherwise, the service ungracefully shuts down at the shutdown timeout. For more information, see the IHostedService interface section.ExecuteAsync
总结
当继承 IHostedService 接口实现 BackgroundService 或者 BackgroundTasks ,其实现类在注入时,不受注入的先后顺序影响。
下面的例子,ConsumerManager 依赖 IKafkaEventBusContainer 的实现:
1 | serviceCollection.AddHostedService<ConsumerManager>(); |
参考:
C#线程池
线程池
“线程池”就是用来存放“线程”的对象池。
作用:因为创建一个线程的代价较高,因此我们使用线程池设法复用线程。
CLR线程池
在.NET中,CLR线程和操作系统线程对应,您可以简单地认为.NET中的Thread对象便封装了一个操作系统线程,并附带一些托管环境下所需要的数据(如GC Handle)。而CLR线程池便是存放这些CLR线程的对象池。Thread对象只有当真正Start了之后,CLR才会创建一个操作系统线程与它绑定。
ThreadPool类的两个静态方法:QueueUserWorkItem和UnsafeUserQueueWorkItem向CLR线程池中添加任务(一个WorkCallback委托对象),这两个方法的区别,在于前者会收集调用方的ExecutionContext,也就是保留了的当前线程的执行信息(如认证或语言文化等),使任务最终会在“创建”时刻的环境中执行——后者就不会。因此,如果比较两个方法的绝对性能,Unsafe方法会略胜一筹。但是平时还是建议使用QueueUserWorkItem方法,因为保留执行上下文会避免很多麻烦事情,且这点性能损耗其实算不上什么。
注:
ASP.NET在得到一个请求后,也会将这个请求处理的任务交由CLR线程池去执行——请注意,它们最多只是添加任务而已,并不表示任务会立即执行。所有添加到CLR线程池的任务都会在合适的时候得以执行——可能马上,也可能要稍等片刻,甚至更久。简单的概括说来,便是线程池内有空闲的线程,或线程池所管理的线程数量还没有达到上限的时候。如果有空闲的线程,线程池就会立即让它领取一个任务执行。如果是第二种情况,线程池便会创建新的Thread对象。由于让操作系统管理太多线程反而会造成性能下降,因此CLR线程池会有一个上限。
对于ASP.NET应用程序来说,CLR线程池容量代表了应用程序最多可以同时执行的请求数量。对于托管在IIS上的ASP.NET执行环境来说,这个值由全局配置决定。这个配置在machine.config文件中system.web/processModel节点中,为maxWorkerThreads属性,它决定了为单个处理器分配的线程数。如果这个值为40,且机器上拥有4个处理器(2 * 2CPU),那么这台机器目前的配置表示在同一时刻,ASP.NET可以同时处理160个请求。
既然有最大值,也就相应有了最小值,它代表了CLR线程池“总是会保留”的最少线程数量。由于线程会占用资源,如在默认情况下,每个线程将获得1MB大小的栈空间3。所以如果在系统中保留太多空闲线程对资源也是一种浪费。因此,CLR线程池在使用大量线程处理完大量任务之后,也会逐步地释放线程,直至到达最小值。CLR线程池的最小线程数量确保了在任务数量较少的情况下,新来的任务可以立即执行,从而省去了创建新线程的时间。在普通应用程序中这个值为“处理器数 * 1”,而在ASP.NET应用程序中这个值配置在machine.config文件中system.web/processModel节点的minWorkerThreads属性中4。
对于processModel节点的数据,ASP.NET只会读取machine.config中的全局配置信息,这意味着我们不能使用web.config为不同应用程序配置不同的参数。如果我们要实现应用程序级别的配置,那么必须使用ThreadPool类中提供的API进行设置。
CLR线程池限制了线程的创建速度不超过每秒2个。这样,即使在某个瞬时获得了大量的任务,CLR线程池也可以使用相对较少的线程来完成所有工作。
但是,还有一种情况也值得考虑。例如,对于一个比较繁忙的Web应用程序来说,一打开便会涌入大量的连接。由于线程的创建速度有限,因此可以执行的请求数量也只能慢慢增加。对于这种您预料到会产生大量线程,而且忙碌状况会持续一段时间的情况,限制线程的创建速度反而会带来损伤效率。这时,您就可以手动设置CLR线程池的最小线程数量。如果此时CLR线程池中拥有的线程数量较少,那么系统就会立即创建一定数量的线程来达到这个最小值。设置和获取CLR线程池最小线程数量的接口为:
1 | public static class ThreadPool |
参考:ThreadPool 类
注意:
无论是设置还是获取到的这些数值,都与处理器数量没有任何关系了。也就是说,在一台2 * 2CPU的机器上运行一个普通的.NET应用程序时:
- 调用GetMaxThreads方法将获得1000,表示CLR线程池最大容量为1000(250 * 4),而不是250。
- 调用SetMinThreads并传入100,表示CLR线程池所拥有的最小线程数量为100,而不是400(100 * 4)。
独立线程池
在一个.NET应用程序中会有一个CLR线程池,可以使用ThreadPool类中的静态方法来使用这个线程池。整个进程内部几乎所有的任务都会依赖这个线程池。由于开发人员对于统一的线程池无法做到精确控制,因此在一些特别的需要就无法满足了。举个最常见例子:控制运算能力。
我们可以简单的认为,在同样的环境下,一个任务使用的线程数量越多,它所获得的运算能力就比另一个线程数量较少的任务要来得多。运算能力自然就涉及到任务执行的快慢。
可以设想一下,有一个生产任务,和一个消费任务,它们使用一个队列做临时存储。在理想情况下,生产和消费的速度应该保持相同,这样可以带来最好的吞吐量。如果生产任务执行较快,则队列中便会产生堆积,反之消费任务就会不断等待,吞吐量也会下降。因此,在实现的时候,我们往往会为生产任务和消费任务分别指派独立的线程池,并且通过增加或减少线程池内线程数量来条件运算能力,使生产和消费的步调达到平衡。
如果需要在同一进程内创建多个线程池,可以借助 SmartThreadPool
IO线程池
IO线程池便是为异步IO服务的线程池。
BeginGetResponse将发起一个利用IOCP的异步IO操作,并在结束时调用HandleAsyncCallback回调函数。那么,这个回调函数是由哪里的线程执行的呢?没错,就是传说中“IO线程池”的线程。.NET在一个进程中准备了两个线程池,除了上篇文章中所提到的CLR线程池之外,它还为异步IO操作的回调准备了一个IO线程池。IO线程池的特性与CLR线程池类似,也会动态地创建和销毁线程,并且也拥有最大值和最小值。
只可惜,IO线程池也仅仅是那“一整个”线程池,CLR线程池的缺点IO线程池也一应俱全。例如,在使用异步IO方式读取了一段文本之后,下一步操作往往是对其进行分析,这就进入了计算密集型操作了。但对于计算密集型操作来说,如果使用整个IO线程池来执行,我们无法有效的控制某项任务的运算能力。
参考:
理解.Net Standard
.NET Standard 是一项 API 规范,每一个特定的版本,都定义了必须实现的基类库(NETStandard.Library)。
如图:

托管框架的每一种实现都有一套自己的基类库。基类库(BCL)包含诸如异常处理、字符串、XML、I/O、网络和集合这样的类。
.NET Standard 是一项实现BCL 的规范。由于.NET 实现需要遵循这项规范,所以应用程序开发人员就不用担心每一种托管框架实现的BCL 不同。
框架类库(FCL),如 WPF、WCF、ASP.NET,不包含在 BCL 中,因此,也就不包含在.NET Standard 中。
.NET Standard 与.NET 实现之间的关系就和 HTML 规范与浏览器之间的关系一样。后者是前者的实现。
因此,.NET Framework、Xamarin 和.NET Core,每一种托管框架都实现了.NET Standard 中的 BCL。随着计算机工业不断推出新的硬件和操作系统,将来还会出现新的.NET 托管框架。该标准让应用程序开发人员知道,他们可以依赖于一套始终如一的 API。
每个.NET 版本都对应一个.NET Standard 版本。
版本对应图:
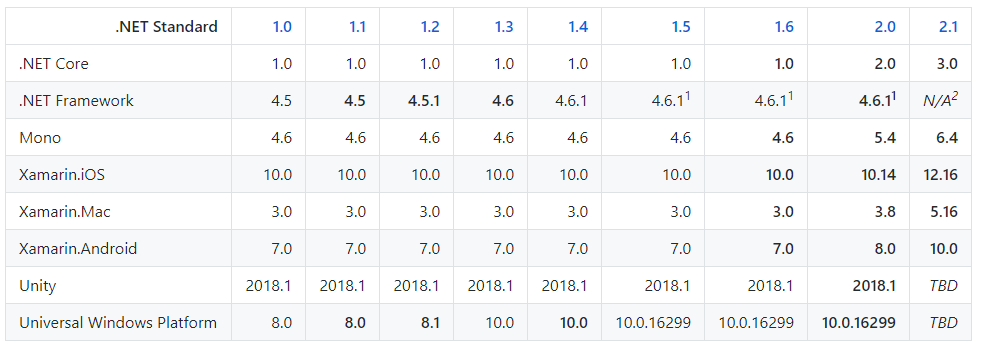
API 一致,将应用程序移植到不同的托管实现以及提供工具都会更简单。
.NET Standard 被定义为一个单独的 NuGet 包,因为所有的.NET 实现都必须支持它。工具变得简单了,因为对于特定的版本,它们有一套相同的 API。你还可以针对多个.NET 实现构建一个库项目。
参考:
TPL DataFlow笔记(2)
TPL DataFlow初探(二)简单的介绍了TDF提供的一些Block,通过对这些Block配置和组合,可以满足很多的数据处理的场景。这一篇将继续介绍与这些Block配置的相关类,和挖掘一些高级功能。
在一些Block的构造函数中,我们常常可以看见需要你输入 DataflowBlockOptions 类型或者它的两个派生类型ExecutionDataflowBlockOptions 和 GroupingDataflowBlockOptions。
DataflowBlockOptions
DataflowBlockOptions 有五个属性:BoundedCapacity,CancellationToken,MaxMessagesPerTask,NameFormat 和 TaskScheduler。
用BoundedCapacity来限定容量
这个属性用来限制一个Block中最多可以缓存数据项的数量,大多数Block都支持这个属性,这个值默认是DataflowBlockOptions.Unbounded = -1,也就是说没有限制。开发人员可以制定这个属性设置数量的上限。那后面的新数据将会延迟。比如说用一个 BufferBlock 连接一个 ActionBlock,如果在 ActionBlock 上面设置了上限,ActionBlock 处理的操作速度比较慢,留在 ActionBlock 中的数据到达了上限,那么余下的数据将留在BufferBlock中,直到 ActionBlock 中的数据量低于上限。这种情况常常会发生在生产者生产的速度大于消费者速度的时候,导致的问题是内存越来越大,数据操作越来越延迟。我们可以通过一个 BufferBlock 连接多个ActionBlock 来解决这样的问题,也就是负载均衡。一个 ActionBlock 满了,就会放到另外一个 ActionBlock 中去了。
用CancellationToken来取消操作
TPL中常用的类型。在Block的构造函数中放入 CancellationToken,Block将在它的整个生命周期中全程监控这个对象,只要在这个Block结束运行(调用Complete方法)前,用 CancellationToken 发送取消请求,该Block将会停止运行,如果Block中还有没有处理的数据,那么将不会再被处理。
用MaxMessagesPerTask控制公平性
每一个Block内部都是异步处理,都是使用TPL的 Task。TDF的设计是在保证性能的情况下,尽量使用最少的任务对象来完成数据的操作,这样效率会高一些,一个任务执行完成一个数据以后,任务对象并不会销毁,而是会保留着去处理下一个数据,直到没有数据处理的时候,Block才会回收掉这个任务对象。但是如果数据来自于多个Source,公平性就很难保证。从其他Source来的数据必须要等到早前的那些Source的数据都处理完了才能被处理。这时我们就可以通过MaxMessagesPerTask 来控制。这个属性的默认值还是 DataflowBlockOptions.Unbounded=-1,表示没有上限。假如这个数值被设置为1的话,那么单个任务只会处理一个数据。这样就会带来极致的公平性,但是将带来更多的任务对象消耗。
用NameFormat来定义Block名称
MSDN上说属性 NameFormat 用来获取或设置查询块的名称时要使用的格式字符串。
Block的名字 Name=string.format(NameFormat, block.GetType ().Name, block.Completion.Id)。所以当我们输入”{0}”的时候,名字就是 block.GetType ().Name,如果我们数据的是”{1}”,那么名字就是block.Completion.Id。如果是“{2}”,那么就会抛出异常。
用TaskScheduler来调度Block行为
TaskScheduler 是非常重要的属性。同样这个类型来源于TPL。每个Block里面都使用 TaskScheduler 来调度行为,无论是源Block和目标Block之间的数据传递,还是用户自定义的执行数据方法委托,都是使用的 TaskScheduler。如果没有特别设置的话,将使用 TaskScheduler.Default(System.Threading.Tasks.ThreadPoolTaskScheduler)来调度。我们可以使用其他的一些继承于 TaskScheduler 的类型来设置这个调度器,一旦设置了以后,Block中的所有行为都会使用这个调度器来执行。.Net Framework 4 中内建了两个 Scheduler ,一个是默认的 ThreadPoolTaskScheduler ,另一个是用于UI线程切换的 SynchronizationContextTaskScheduler 。如果你使用的Block设计到UI的话,那可以使用后者,这样在UI线程切换上面将更加方便。
.Net Framework 4.5 中,还有一个类型被加入到 System.Threading.Tasks 名称空间下:ConcurrentExclusiveSchedulerPair 。这个类是两个 TaskScheduler 的组合。它提供两个 TaskScheduler: ConcurrentScheduler 和 ExclusiveScheduler;我们可以把这两个 TaskScheduler 构造进要使用的Block中。他们保证了在没有排他任务的时候(使用 ExclusiveScheduler 的任务),其他任务(使用ConcurrentScheduler)可以同步进行,当有排他任务在运行的时候,其他任务都不能运行。其实它里面就是一个读写锁。这在多个Block操作共享资源的问题上是一个很方便的解决方案。
1 | public ActionBlock<int> readerAB1; |
用MaxDegreeOfParallelism来并行处理
通常,Block中处理数据都是单线程的,一次只能处理一个数据,比如说 ActionBlock 中自定义的代理。使用 MaxDegreeOfParallelism 可以让你并行处理这些数据。属性的定义是最大的并行处理个数。如果定义成-1的话,那就是没有限制。用户需要在实际情况中选择这个值的大小,并不是越大越好。如果是平行处理的话,还应该考虑是否有共享资源。
TDF中的负载均衡
我们可以使用Block很方便的构成一个生产者消费者的模式来处理数据。当生产者产生数据的速度快于消费者的时候,消费者Block的Buffer中的数据会越来越多,消耗大量的内存,数据处理也会延时。这时,我们可以用一个生产者Block连接多个消费者Block来解决这个问题。由于多个消费者Block一定是并行处理,所以对共享资源的处理一定要做同步处理。
使用BoundedCapacity属性来实现
当连接多个 ActionBlock 的时候,可以通过设置 ActionBlock 的 BoundedCapacity 属性。当第一个满了,就会放到第二个,第二个满了就会放到第三个。
1 | public BufferBlock<int> bb = new BufferBlock<int>(); |
TPL DataFlow笔记(1)
属性 TPL Dataflow 是微软面向高并发应用而推出的一个类库。借助于异步消息传递与管道,它可以提供比线程池更好的控制,也比手工线程方式具备更好的性能。我们常常可以消息传递,生产-消费模式或Actor-Agent模式中使用。在TDF是构建于 Task Parallel Library (TPL)之上的,它是我们开发高性能,高并发的应用程序的又一利器。
TDF的主要作用就是 Buffering Data 和 Processing Data ,在TDF中,有两个非常重要的接口,ISourceBlock<T> 和 ITargetBlock<T> 接口。继承于 ISourceBlock<T> 的对象时作为提供数据的数据源对象-生产者,而继承于 ITargetBlock<T> 接口类主要是扮演目标对象-消费者。在这个类库中,System.Threading.Tasks.Dataflow 名称空间下,提供了很多以Block名字结尾的类,ActionBlock,BufferBlock,TransformBlock,BroadcastBlock 等9个Block,我们在开发中通常使用单个或多个Block组合的方式来实现一些功能。
支持的版本:
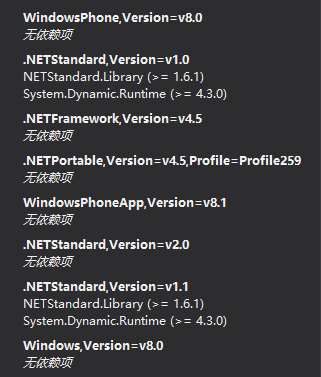
备注:
TPL 数据流库(System.Threading.Tasks.Dataflow 命名空间)不随 .NET 一起分发。 若要在 Visual Studio 中安装 System.Threading.Tasks.Dataflow 命名空间,请打开项目,选择“项目” 菜单中的“管理 NuGet 包” ,再在线搜索 System.Threading.Tasks.Dataflow 包。 或者,若要使用 .NET Core CLI 进行安装,请运行 dotnet add package System.Threading.Tasks.Dataflow。
BufferBlock
BufferBlock 是TDF中最基础的 Block。BufferBlock 提供了一个有界限或没有界限的 Buffer,该 Buffer 中存储T。该 Block 很像 BlockingCollection<T> 。可以用过 Post 往里面添加数据,也可以通过Receive 方法阻塞或异步的的获取数据,数据处理的顺序是 FIFO 的。它也可以通过Link向其他 Block 输出数据。
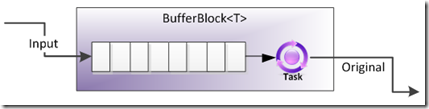
简单的同步的生产者消费者代码示例:
1 | private static BufferBlock<int> m_buffer = new BufferBlock<int>(); |
ActionBlock
ActionBlock 实现 ITargetBlock,说明它是消费数据的,也就是对输入的一些数据进行处理。它在构造函数中,允许输入一个委托,来对每一个进来的数据进行一些操作。如果使用Action(T) 委托,那说明每一个数据的处理完成需要等待这个委托方法结束,如果使用了 Func<TInput, Task>) 来构造的话,那么数据的结束将不是委托的返回,而是Task的结束。默认情况下,ActionBlock 会 FIFO 的处理每一个数据,而且一次只能处理一个数据,一个处理完了再处理第二个,但也可以通过配置来并行的执行多个数据。

1 | public ActionBlock<int> abSync = new ActionBlock<int>((i) => |
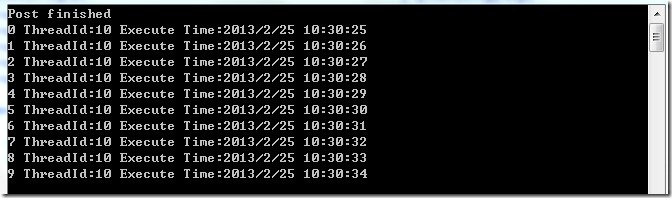
可见,ActionBlock 是顺序处理数据的,这也是 ActionBlock 一大特性之一。主线程在往 ActionBlock 中 Post 数据以后马上返回,具体数据的处理是另外一个线程来做的。数据是异步处理的,但处理本身是同步的,这样在一定程度上保证数据处理的准确性。下面的例子是使用async和await。
1 | public ActionBlock<int> abSync2 = new ActionBlock<int>(async (i) => |
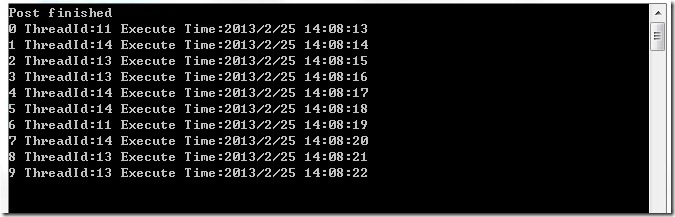
虽然还是1秒钟处理一个数据,但是处理数据的线程会有不同。
如果你想异步处理多个消息的话,ActionBlock 也提供了一些接口,让你轻松实现。在 ActionBlock 的构造函数中,可以提供一个 ExecutionDataflowBlockOptions 的类型,让你定义 ActionBlock 的执行选项,在下面了例子中,我们定义了 MaxDegreeOfParallelism 选项,设置为3。目的的让 ActionBlock 中的Item最多可以3个并行处理。
1 | public ActionBlock<int> abAsync = new ActionBlock<int>((i) => |
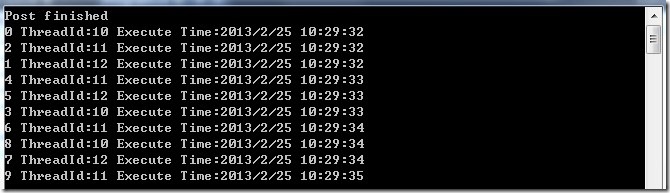
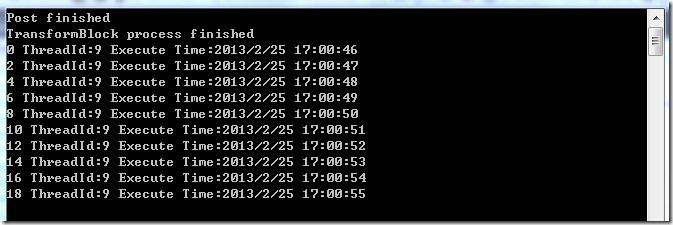
运行程序,我们看见,每3个数据几乎同时处理,并且他们的线程ID也是不一样的。
ActionBlock 也有自己的生命周期,所有继承 IDataflowBlock 的类型都有 Completion 属性和 Complete 方法。调用 Complete 方法是让 ActionBlock 停止接收数据,而 Completion 属性则是一个Task,是在 ActionBlock 处理完所有数据时候会执行的任务,我们可以使用 Completion.Wait() 方法来等待 ActionBlock 完成所有的任务,Completion 属性只有在设置了 Complete 方法后才会有效。
1 | public void TestAsync() |
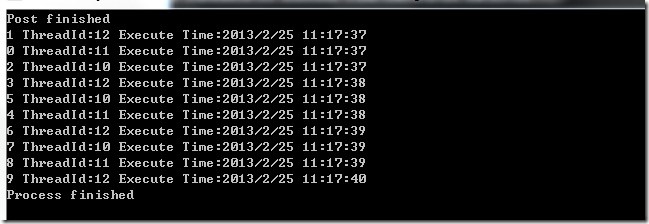
TransformBlock
TransformBlock 是TDF提供的另一种 Block ,顾名思义它常常在数据流中充当数据转换处理的功能。在TransformBlock 内部维护了2个 Queue,一个 InputQueue,一个 OutputQueue。InputQueue 存储输入的数据,而通过 Transform 处理以后的数据则放在 OutputQueue,OutputQueue 就好像是一个 BufferBlock。最终我们可以通过 Receive 方法来阻塞的一个一个获取 OutputQueue 中的数据。 TransformBlock 的 Completion.Wait() 方法只有在 OutputQueue 中的数据为0的时候才会返回。

举个例子,我们有一组网址的URL,我们需要对每个URL下载它的HTML数据并存储。那我们通过如下的代码来完成:
1 | public TransformBlock<string, string> tbUrl = new TransformBlock<string, string>((url) => |
当然,Post 操作和 Receive 操作可以在不同的线程中进行,Receive 操作同样也是阻塞操作,在 OutputQueue 中有可用的数据时,才会返回。
TransformManyBlock
TransformManyBlock 和 TransformBlock 非常类似,关键的不同点是,TransformBlock 对应于一个输入数据只有一个输出数据,而 TransformManyBlock 可以有多个,及可以从 InputQueue 中取一个数据出来,然后放多个数据放入到 OutputQueue 中。

1 | TransformManyBlock<int, int> tmb = new TransformManyBlock<int, int>((i) => { return new int[] { i, i + 1 }; }); |

BroadcastBlock
BroadcastBlock 的作用不像 BufferBlock ,它是使命是让所有和它相联的目标 Block 都收到数据的副本,这点从它的命名上面就可以看出来了。还有一点不同的是,BroadcastBlock 并不保存数据,在每一个数据被发送到所有接收者以后,这条数据就会被后面最新的一条数据所覆盖。如没有目标 Block 和 BroadcastBlock 相连的话,数据将被丢弃。但 BroadcastBlock 总会保存最后一个数据,不管这个数据是不是被发出去过,如果有一个新的目标 Block 连上来,那么这个 Block 将收到这个最后一个数据。
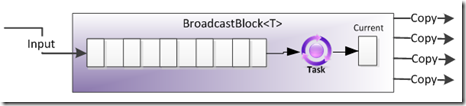
1 | BroadcastBlock<int> bb = new BroadcastBlock<int>((i) => { return i; }); |

如果我们在Post以后再添加连接Block的话,那些Block就只会收到最后一个数据了。
1 | public void TestSync() |
WriteOnceBlock
如果说 BufferBlock 是最基本的 Block ,那么 WriteOnceBock 则是最最简单的 Block 。它最多只能存储一个数据,一旦这个数据被发送出去以后,这个数据还是会留在Block中,但不会被删除或被新来的数据替换,同样所有的接收者都会收到这个数据的备份。
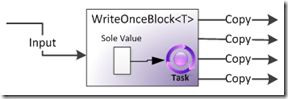
和BroadcastBlock同样的代码,但是结果不一样:
1 | WriteOnceBlock<int> bb = new WriteOnceBlock<int>((i) => { return i; }); |

WriteOnceBock只会接收一次数据。而且始终保留那个数据。
同样使用Receive方法来获取数据也是一样的结果,获取到的都是第一个数据:
1 | public void TestReceive() |

BatchBlock

BatchBlock 提供了能够把多个单个的数据组合起来处理的功能,如上图。应对有些需求需要固定多个数据才能处理的问题。在构造函数中需要制定多少个为一个 Batch,一旦它收到了那个数量的数据后,会打包放在它的 OutputQueue 中。当 BatchBlock 被调用 Complete 告知 Post 数据结束的时候,会把 InputQueue 中余下的数据打包放入 OutputQueue 中等待处理,而不管 InputQueue 中的数据量是不是满足构造函数的数量。
1 | BatchBlock<int> bb = new BatchBlock<int>(3); |

BatchBlock 执行数据有两种模式:贪婪模式和非贪婪模式。贪婪模式是默认的。贪婪模式是指任何Post到BatchBlock,BatchBlock 都接收,并等待个数满了以后处理。非贪婪模式是指 BatchBlock 需要等到构造函数中设置的 BatchSize 个数的 Source 都向 BatchBlock 发数据,Post 数据的时候才会处理。不然都会留在Source的Queue中。也就是说 BatchBlock 可以使用在每次从N个 Source 那个收一个数据打包处理或从1个 Source 那里收N个数据打包处理。这里的Source是指其他的继承 ISourceBlock 的,用 LinkTo 连接到这个BatchBlock 的 Block 。
在另一个构造参数中 GroupingDataflowBlockOptions,可以通过设置 Greedy 属性来选择是否贪婪模式和 MaxNumberOfGroups 来设置最大产生Batch的数量,如果到达了这个数量,BatchBlock 将不会再接收数据。
JoinBlock

JoinBlock 一看名字就知道是需要和两个或两个以上的 Source Block 相连接的。它的作用就是等待一个数据组合,这个组合需要的数据都到达了,它才会处理数据,并把这个组合作为一个 Tuple 传递给目标 Block。举个例子,如果定义了 JoinBlock<int, string> 类型,那么 JoinBlock 内部会有两个 ITargetBlock,一个接收int类型的数据,一个接收string类型的数据。那只有当两个 ITargetBlock 都收到各自的数据后,才会放到JoinBlock的OutputQueue 中,输出。
1 | JoinBlock<int, string> jb = new JoinBlock<int, string>(); |

BatchedJoinBlock

BatchedJoinBlock 一看就是 BacthBlock 和 JoinBlick 的组合。JoinBlick 是组合目标队列的一个数据,而 BatchedJoinBlock 是组合目标队列的N个数据,当然这个N可以在构造函数中配置。如果我们定义的是BatchedJoinBlock<int, string>, 那么在最后的 OutputQueue 中存储的是 Tuple<IList<int>, IList<string>>,也就是说最后得到的数据是 Tuple<IList<int>, IList<string>>。它的行为是这样的,还是假设上文的定义,BatchedJoinBlock<int, string>, 构造 BatchSize 输入为3。那么在这个BatchedJoinBlock 种会有两个 ITargetBlock,会接收Post的数据。那什么时候会生成一个 Tuple<IList<int>,IList<string>> 到 OutputQueue 中呢,测试下来并不是我们想的需要有3个int数据和3个string数据,而是只要2个 ITargetBlock 中的数据个数加起来等于3就可以了。3和0,2和1,1和2或0和3的组合都会生成 Tuple<IList<int>,IList<string>> 到 OutputQueue 中。可以参看下面的例子:
1 | BatchedJoinBlock<int, string> bjb = new BatchedJoinBlock<int, string>(3); |
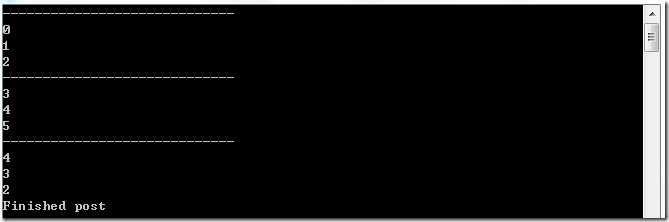
最后剩下的一个数据1,由于没有满3个,所以一直被保留在Target2中。
TDF中最有用的功能之一就是多个 Block 之间可以组合应用。ISourceBlock 可以连接 ITargetBlock ,一对一,一对多,或多对多。下面的例子就是一个 TransformBlock 和一个 ActionBlock 的组合。TransformBlock 用来把数据*2,并转换成字符串,然后把数据扔到 ActionBlock 中,而 ActionBlock 则用来最后的处理数据打印结果。
1 | public ActionBlock<string> abSync = new ActionBlock<string>((i) => |
参考:
hash算法笔记
什么是Hash
Hash也称散列、哈希,对应的英文都是Hash。Hash算法,也叫散列算法(Hash Algorithm),又称哈希算法,杂凑算法,是一种从任意文件中创造小的数字「指纹」的方法。
基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。活动开发中经常使用的MD5和SHA都是历史悠久的Hash算法。
echo md5(“这是一个测试文案”);
1 | // 输出结果:2124968af757ed51e71e6abeac04f98d |
在这个例子里,这是一个测试文案是原始值,2124968af757ed51e71e6abeac04f98d 就是经过hash算法得到的Hash值。整个Hash算法的过程就是把原始任意长度的值空间,映射成固定长度的值空间的过程。
Hash的特点
一个优秀的 hash 算法,将能实现:
- 正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
- 逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
- 输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
- 冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
但在不同的使用场景中,如数据结构和安全领域里,其中对某一些特点会有所侧重。
Hash流行的算法
目前流行的 Hash 算法包括 MD5、SHA-1 和 SHA-2。
MD4(RFC 1320)是 MIT 的 Ronald L. Rivest 在 1990 年设计的,MD 是 Message Digest 的缩写。其输出为 128 位。MD4 已证明不够安全。
MD5(RFC 1321)是 Rivest 于1991年对 MD4 的改进版本。它对输入仍以 512 位分组,其输出是 128 位。MD5 比 MD4 复杂,并且计算速度要慢一点,更安全一些。MD5 已被证明不具备”强抗碰撞性”。
SHA (Secure Hash Algorithm)是一个 Hash 函数族,由 NIST(National Institute of Standards and Technology)于 1993 年发布第一个算法。目前知名的 SHA-1 在 1995 年面世,它的输出为长度 160 位的 hash 值,因此抗穷举性更好。SHA-1 设计时基于和 MD4 相同原理,并且模仿了该算法。SHA-1 已被证明不具”强抗碰撞性”。
为了提高安全性,NIST 还设计出了 SHA-224、SHA-256、SHA-384,和 SHA-512 算法(统称为 SHA-2),跟 SHA-1 算法原理类似。SHA-3 相关算法也已被提出。
注意:MD5在数年前就已经不被推荐作为应用中的散列算法方案,取代它的是SHA家族算法,也就是安全散列算法(Secure Hash Algorithm,缩写为SHA)。
git等版本控制工具使用SHA1等散列函数检查文件。
SHA家族算法以及SHA1碰撞
安全散列算法与MD5算法本质上的算法是类似的,但安全性要领先很多——这种领先型更多的表现在碰撞攻击的时间开销更大,当然相对应的计算时间也会慢一点。
SHA家族算法的种类很多,有SHA0、SHA1、SHA256、SHA384等等,它们的计算方式和计算速度都有差别。其中SHA1是现在用途最广泛的一种算法。包括GitHub在内的众多版本控制工具以及各种云同步服务都是用SHA1来区别文件,很多安全证书或是签名也使用SHA1来保证唯一性。长期以来,人们都认为SHA1是十分安全的,至少大家还没有找到一次碰撞案例。
但这一事实在2017年2月破灭了。CWI和Google的研究人员们成功找到了一例SHA1碰撞,而且很厉害的是,发生碰撞的是两个真实的、可阅读的PDF文件。这两个PDF文件内容不相同,但SHA1值完全一样。(对于这件事的影响范围及讨论,可参考知乎上的讨论:如何评价 2 月 23 日谷歌宣布实现了 SHA-1 碰撞?)
所以,对于一些大的商业机构来说, MD5 和 SHA1 已经不够安全,推荐至少使用 SHA2-256 算法。
murmurhash算法
murmur:低语,嘟囔
MurmurHash是一种非加密型哈希函数,适用于一般的哈希检索操作。由Austin Appleby在2008年发明,并且有多个变种,都已经发布到了公有领域(public domain)。与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。
特点:对于规律性较强的key,MurmurHash的随机分布特性表现更良好。与加密散列函数不同,它不是专门设计为难以被对手逆转,因此不适用于加密目的。
Redis在实现字典时用到了两种不同的哈希算法,MurmurHash便是其中一种(另一种是djb),在Redis中应用十分广泛,包括数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。发明算法的作者被邀到google工作,该算法最新版本是MurmurHash3,基于MurmurHash2改进了一些小瑕疵,使得速度更快,实现了32位(低延时)、128位HashKey,尤其对大块的数据,具有较高的平衡性与低碰撞率。
版本:
Murmurhash3
2018年的版本是Murmurhash3,它产生一个32位或128位散列值。 使用128位时,x86和x64版本不会生成相同的值,因为算法针对各自的平台进行了优化。
Murmurhash2
旧的Murmurhash2 产生一个32位或64位的值。 较慢版本的Murmurhash2可用于大端和对齐的机器。 Murmurhash2A变体添加了Merkle-Damgård构造,因此可以逐渐调用它。 有两种变体生成64位值; 针对64位处理器的Murmurhash64A和针对32位处理器的Murmurhash64B。 Murmurhash2-160生成160位散列,而Murmurhash1已过时。
一致性hash算法
参考:
一致性hash算法
一致性 hash 算法 (consistent hashing)
转载自:
一致性hash算法 - consistent hashing
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing…
hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
环形hash 空间
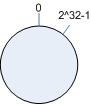
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。
图1 环形 hash 空间
把对象映射到hash 空间
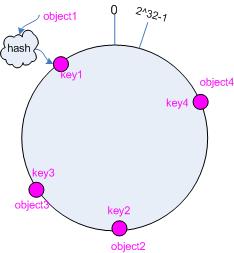
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;
图2 4个对象的 key 值分布
把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash 值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;
图3 cache 和对象的 key 值分布
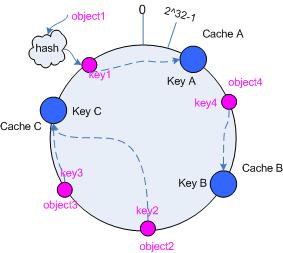
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为 hash 输入。
把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2 和 object3 对应到 cache C ; object4 对应到 cache B ;
考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时, cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
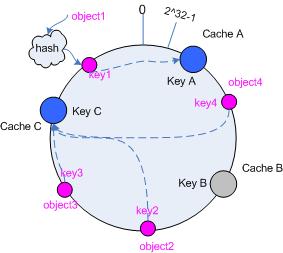
移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。
图4 Cache B 被移除后的 cache 映射
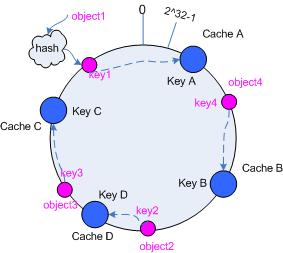
添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和 object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。
图5 添加 cache D 后的映射关系
虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。
图 6 引入“虚拟节点”后的映射关系
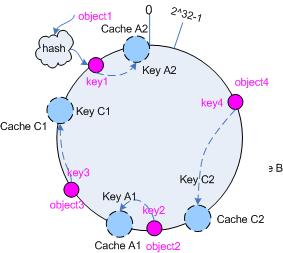
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache 时的映射关系如图 7 所示。
图7 查询对象所在 cache
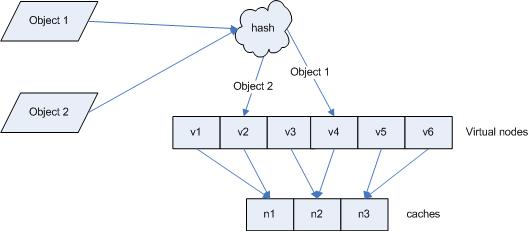
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为 202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
C#代码实现
.NET中间语言(IL)
转载自:
.NET CLR 和 Java VM 都是堆栈式虚拟机(Stack-Based VM),也就是说,它们的指令集(Instruction Set)都是采用堆栈运算的方式:执行时的数据都是先放在堆栈中,再进行运算。 Java VM 有约 200 个指令(Instruction),每个指令都是 1 byte 的 opcode(操作码),后面接不等数目的参数;.NET CLR 有超过 220 个指令,但是有些指令使用相同的 opcode,所以 opcode 的 数目比指令数略少。 特别注意,.NET 的 opcode 长度并不固定,大部分的 opcode 长度是 1 byte,少部分是 2 byte。
本文章以一个实际的例子,让你了解堆栈式 VM 的运作原理,并对 .NET IL(Intermediate Language)有最基本的领略。
下面是一个简单的 C# 原始码:
1 | using System; |
将此原始码编译之后,可以得到一个 EXE 档案。 我们可以透过 ILDASM. EXE 来反组译 EXE 以观察 IL。 我将 Main() 的 IL 反组译条列如下,这里共有十八道 IL 指令,有的指令(例如 ldstr 与 box)后面需要接参数,有的指令(例如 ldc.i4.1 与 add)后面不需要接参数。
1 | ldc.i4.1 |
此程序执行时,关键的内存有三种,分别是:
Managed Heap:这是动态配置(Dynamic Allocation)的内存,由 Garbage Collector(GC)在执行时自动管理,整个 Process 共享一个 Managed Heap。
Call Stack:这是由 .NET CLR 在执行时自动管理的内存,每个 Thread 都有自己专属的 Call Stack。 每呼叫一次 method,就会使得 Call Stack 上多了一个 Record Frame;呼叫完毕之后,此 Record Frame 会被丢弃。 一般来说,Record Frame 内纪录着 method 参数(Parameter)、返回地址(Return Address)、以及局部变量(Local Variable)。 Java VM 和 .NET CLR 都是使用 0, 1, 2… 编号的方式来识别局部变量。
Evaluation Stack:这是由 .NET CLR 在执行时自动管理的内存,每个 Thread 都有自己专属的 Evaluation Stack。 前面所谓的堆栈式虚拟机,指的就是这个堆栈。
后面有一连串的示意图,用来解说在执行时此三种内存的变化。 首先,在进入 Main() 之后,尚未执行任何指令之前,内存的状况如图 1 所示:
.jpg)
图 1
接着要执行第一道指令 ldc.i4.1。 此指令的意思是:在 Evaluation Stack 置入一个 4 byte 的常数,其值为 1。 执行完此道指令之后,内存的变化如图 2 所示:
.jpg)
图 2
接着要执行第二道指令 stloc.0。 此指令的意思是:从 Evaluation Stack 取出一个值,放到第 0 号变量(V0)中。 这里的第 0 号变量其实就是原始码中的 i。 执行完此道指令之后,内存的变化如图 3 所示:
.jpg)
图 3
后面的第三道指令和第五道指令雷同于第一道指令,且第四道指令和第六道指令雷同于第二道指令。 为了节省篇幅,我不在此一一赘述。 提醒大家第 1 号变量(V1)其实就是原始码中的 j,且第 2 号变量(V2)其实就是源码中的 k。 图 47 分别是执行完第三六道指令之后,内存的变化图:
.jpg)
图 4
.jpg)
图 5
.jpg)
图 6
.jpg)
图 7
接着要执行第七道指令 ldloc.0 以及第八道指令 ldloc.1:分别将 V0(也就是 i)和 V1(也就是 j)的值放到 Evaluation Stack,这是相加前的准备动作。 图 8 与图 9 分别是执行完第七、第八道指令之后,内存的变化图:
.jpg)
图 8
.jpg)
图 9
接着要执行第九道指令 add。 此指令的意思是:从 Evaluation Stack 取出两个值(也就是 i 和 j),相加之后将结果放回 Evaluation Stack 中。 执行完此道指令之后,内存的变化如图 10 所示:
.jpg)
图 10
接着要执行第十道指令 ldloc.2。 此指令的意思是:分别将 V2(也就是 k)的值放到 Evaluation Stack,这是相加前的准备动作。 执行完此道指令之后,内存的变化如图 11 所示:
.jpg)
图 11
接着要执行第十一道指令 add。 从 Evaluation Stack 取出两个值,相加之后将结果放回 Evaluation Stack 中,此为 i+j+k 的值。 执行完此道指令之后,内存的变化如图 12 所示:
.jpg)
图 12
接着要执行第十二道指令 stloc.3。 从 Evaluation Stack 取出一个值,放到第 3 号变量(V3)中。 这里的第3号变量其实就是原始码中的 answer。 执行完此道指令之后,内存的变化如图 13 所示:
.jpg)
图 13
接着要执行第十三道指令 ldstr “i+j+k=”。 此指令的意思是:将 “i+j+k=” 的 Reference 放进 Evaluation Stack。 执行完此道指令之后,内存的变化如图 14 所示:
.jpg)
图 14
接着要执行第十四道指令 ldloc.3。 将 V3 的值放进 Evaluation Stack。 执行完此道指令之后,内存的变化如图 15 所示:
.jpg)
图 15
接着要执行第十五道指令 box [mscorlib]System.Int32。 此指令的意思是:从 Evaluation Stack 中取出一个值,将此 Value Type 包装(box)成为 Reference Type。 执行完此道指令之后,内存的变化如图 16 所示:
.jpg)
图 16
接着要执行第十六道指令 call string [mscorlib] System.String::Concat(object, object)。 此指令的意思是:从 Evaluation Stack 中取出两个值,此二值皆为 Reference Type,下面的值当作第一个参数,上面的值当作第二个参数,呼叫 mscorlib.dll 所提供的 System.String.Concat() method 来将此二参数进行字符串接合(String Concatenation),将接合出来的新字符串放在 Managed Heap,将其 Reference 放进 Evaluation Stack。 值得注意的是:由于 System.String.Concat() 是 static method,所以此处使用的指令是 call,而非 callvirt(呼叫虚拟)。 执行完此道指令之后,内存的变化如图 17 所示:
.jpg)
图 17
请注意:此时 Managed Heap 中的 Int32(6) 以及 String(“i+j+k=”) 已经不再被参考到,所以变成垃圾,等待 GC 的回收。
接着要执行第十七道指令 call void [mscorlib] System.Console::WriteLine(string)。 此指令的意思是:从 Evaluation Stack 中取出一个值,此值为 Reference Type,将此值当作参数,呼叫 mscorlib.dll 所提供的 System.Console.WriteLine() method 来将此字符串显示在 Console 窗口上。 System.Console.WriteLine() 也是 static method。 执行完此道指令之后,内存的变化如图 18 所示:
.jpg)
图 18
接着要执行第十八道指令 ret。 此指令的意思是:结束此次呼叫(也就是 Main 的呼叫)。 此时会检查 Evaluation Stack 内剩下的数据,由于 Main() 宣告不需要传出值(void),所以 Evaluation Stack 内必须是空的,本范例符合这样的情况,所以此时可以顺利结束此次呼叫。 而 Main 的呼叫一结束,程序也随之结束。 执行完此道指令之后(且在程序结束前),内存的变化如图 19 所示:
.jpg)
图 19
透过此范例,读者应该可以对于 IL 有最基本的认识。 对 IL 感兴趣的读者应该自行阅读 Serge Lidin 所著的《Inside Microsoft .NET IL Assembler》(Microsoft Press 出版)。 我认为:熟知 IL 每道指令的作用,是 .NET 程序员必备的知识。.NET 程序员可以不会用 IL Assembly 写程序,但是至少要看得懂 ILDASM 反组译出来的 IL 组合码。