认识32位64位Windows系统
Wow64
Wow64,全称是32bit Windows On 64bit Windows(64位Windows上的32位Windows)。
Windows系统的主要系统文件都是放在一个叫做System32的文件夹中的。为了能同时放下两套系统文件,Windows会在64位的系统上,增加了一个文件夹,叫SysWow64。
总结:
1 | SysWow64文件夹,是64位Windows,用来存放32位Windows系统文件的地方,而System32文件夹,是用来存放64位程序文件的地方。 |
参考:
dll文件32位64位检测工具以及Windows文件夹SysWow64的坑
【结果很简单,过程很艰辛】记阿里云Ons消息队列服务.NET接口填坑过程
分布式事务整理笔记
事务定义
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种 “要么什么都不做,要么做全套(All or Nothing)” 机制。
数据库事务
一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
1,为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
2,当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
数据库事务拥有以下四个特性,ACID 特性。
A 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
C 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
I 隔离性(Isolation)或独立性:多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
D 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
分布式事务
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的 分布式系统 的不同节点之上。
在应用程序只部署在一台计算机,数据库只部署在一台计算机的情况下,事务的ACID四个特性很容易全部满足。
但是单机的处理能力很容易达到上限,此时必须使用分布式系统。在分布式环境下,应用程序可能部署在多台计算机,并且可能有多个不同的应用程序参与到同一个事务中;数据库也可能部署在多台计算机,并且多个不同的数据库可能会参与到同一个事务中。一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务的基础
CAP
CAP定理,又被叫作布鲁尔定理。
C (一致性):对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
A (可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回50,而不是返回40。
P (分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里个集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
分布式系统中,网络无法100%可靠,分区其实是一个必然现象,如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是A又不允许,所以分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
对于CP来说,放弃可用性,追求一致性和分区容错性,我们的zookeeper其实就是追求的强一致。
对于AP来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的BASE也是根据AP来扩展。
CAP理论中是忽略网络延迟,也就是当事务提交时,从节点A复制到节点B,但是在现实中这个是明显不可能的,所以总会有一定的时间是不一致。同时CAP中选择两个,比如你选择了CP,并不是叫你放弃A。因为P出现的概率实在是太小了,大部分的时间你仍然需要保证CA。就算分区出现了你也要为后来的A做准备,比如通过一些日志的手段,是其他机器回复至可用。
BASE
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写,是对CAP中AP的一个扩展。
- 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
- 软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是CAP中的不一致。
- 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
BASE解决了CAP中理论没有网络延迟,在BASE中用软状态和最终一致,保证了延迟后的一致性。BASE和 ACID 是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
分布式事务方案
基于XA协议的2PC(2阶段提交)
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA实现分布式事务的原理如下:
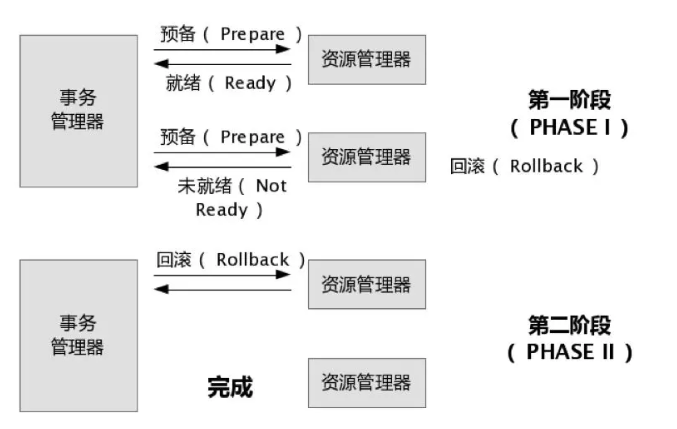
两阶段提交,是实现分布式事务的成熟方案。
- 第一阶段是表决阶段,事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段是执行阶段,事务协调器要求每个数据库提交数据,或者回滚数据。
优点: 尽量保证了数据的强一致,实现成本较低,XA目前在商业数据库支持的比较理想,在MySQL(MySQL5.5开始支持)数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
缺点:
- 单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
- 同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
- 数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
总的来说,XA协议比较简单,但是其单点问题,以及不能支持高并发(由于同步阻塞)依然是其最大的弱点。XA协议已在业界成熟运行数十年,但目前它在互联网海量流量的应用场景中,吞吐量这个瓶颈变得十分致命,因此很少被用到。
两阶段提交可以满足ACID,但代价是吞吐量。例如,数据库需要频繁地对资源上锁等等。而且更致命的是,资源被锁住的时间相对较长—-在第一阶段即需要上锁,第二阶段才能解锁,依赖于所有分支的最慢者—-这期间没有任何人可以对该资源进行修改。
TCC
TCC(Try、Confirm、Cancel)是两阶段提交的一个变种。TCC提供了一个框架,需要应用程序按照该框架编程,将业务逻辑的每个分支都分为Try、Confirm、Cancel三个操作集。TCC让应用程序自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
TCC事务机制相比于上面介绍的XA,解决了其几个缺点:
- 1.解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
- 2.同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
- 3.数据一致性,有了补偿机制之后,由业务活动管理器控制一致性
流程图:
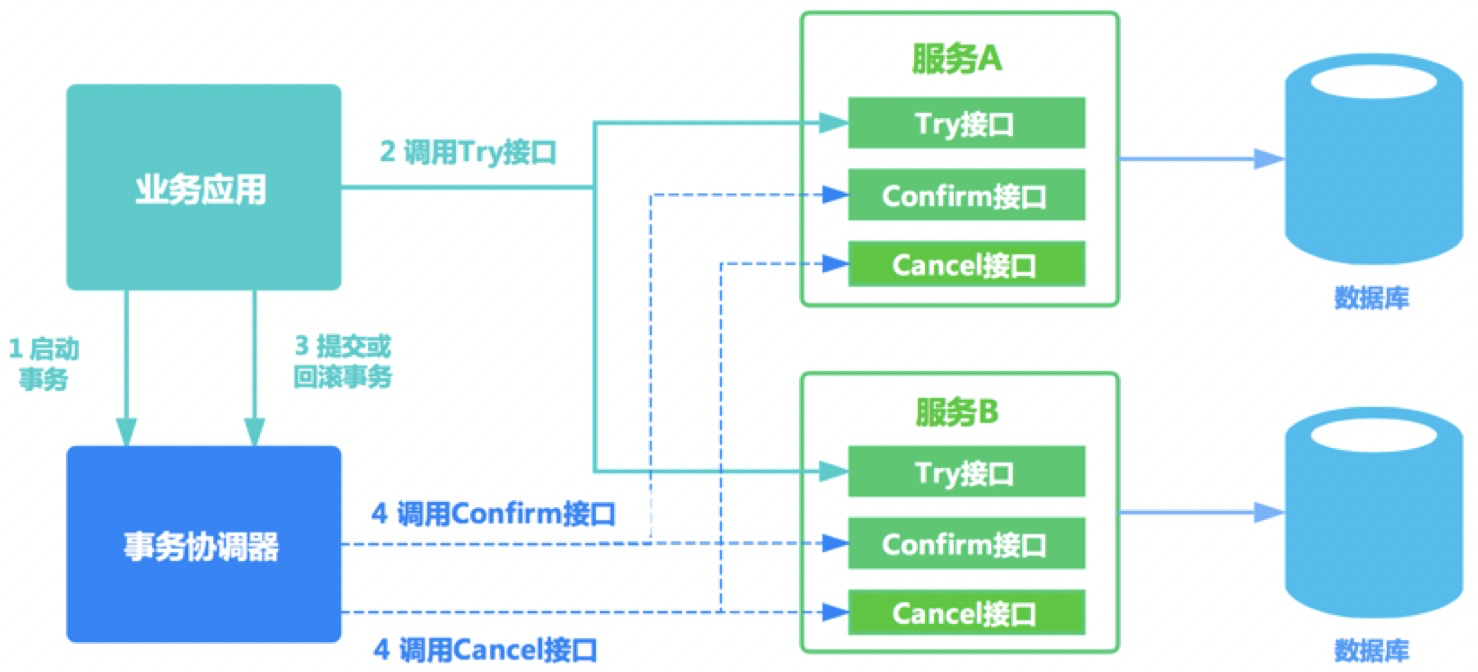
Try阶段:尝试执行,完成所有业务检查(一致性),预留必须业务资源(准隔离性)
Confirm阶段:确认执行真正执行业务,不作任何业务检查,只使用Try阶段预留的业务资源,Confirm操作满足幂等性。要求具备幂等设计,Confirm失败后需要进行重试。
Cancel阶段:取消执行,释放Try阶段预留的业务资源
Cancel操作满足幂等性Cancel阶段的异常和Confirm阶段异常处理方案基本上一致。
以一个典型的淘宝订单为例,按照TCC框架,应用需要在Try阶段将商品的库存减去,将买家支付宝账户中的相应金额扣掉,在临时表中记录下商品的数量,订单的金额等信息;另外再编写Confirm的逻辑,即在临时表中删除相关记录,生成订单,告知CRM、物流等系统,等等;以及Cancel逻辑,即恢复库存和买家账户金额,删除临时表相关记录。
很明显,最终一致性部分牺牲了ACID中的C和I,但它带来了可观的收益:资源不再需要长时间上锁,极大地提高了吞吐量。
最终一致性在互联网应用场景中被广泛用做吞吐量和ACID的妥协点。
在前面TCC的例子。在这个流程中,商品库存和买家余额都没有被锁住,因此可以得到很高的吞吐量。但在交易进行中,商品库存和买家余额的变化就已经被外界感知到,而物流系统却可能还没有相应的记录,此时数据是不一致的,但最终(无论是Confirm阶段结束后,还是Cancel阶段结束后)它们会一致。
TXC
TXC(Taobao Transaction Constructor)是阿里巴巴的一个分布式事务中间件,它可以通过极少的代码侵入,实现分布式事务。
在大部分情况下,应用只需要引入TXC Client的jar包,进行几项简单配置,以及以行计的代码改造,即可轻松保证分布式数据一致性。
TXC同时提供了丰富的编程和配置策略,以适应各种长尾的应用需求。
实现原理是在执行SQL之前,先查询SQL的影响数据,然后保存执行的SQL快走信息和创建锁。当需要回滚的时候就采用这些记录数据回滚数据库,目前锁实现依赖redis分布式锁控制。
TXC的目标应用场景是:解决在分布式应用中,多条数据库记录被修改而可能带来的一致性问题;该分布式应用可以接受最终一致性;该应用的事务改造对工作量有较严格的限制。
LCN
原理:LCN模式是通过代理Connection的方式实现对本地事务的操作,然后在由TxManager统一协调控制事务。当本地事务提交回滚或者关闭连接时将会执行假操作,该代理的连接将由LCN连接池管理。
参考:TX-LCN
本地消息表 (异步确保)
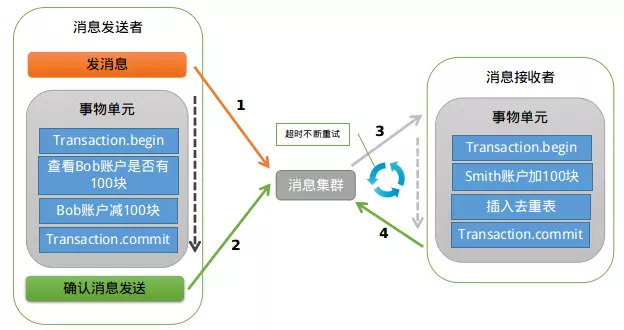
本地消息表是国外的 ebay 搞出来的一套方案,如图所示:
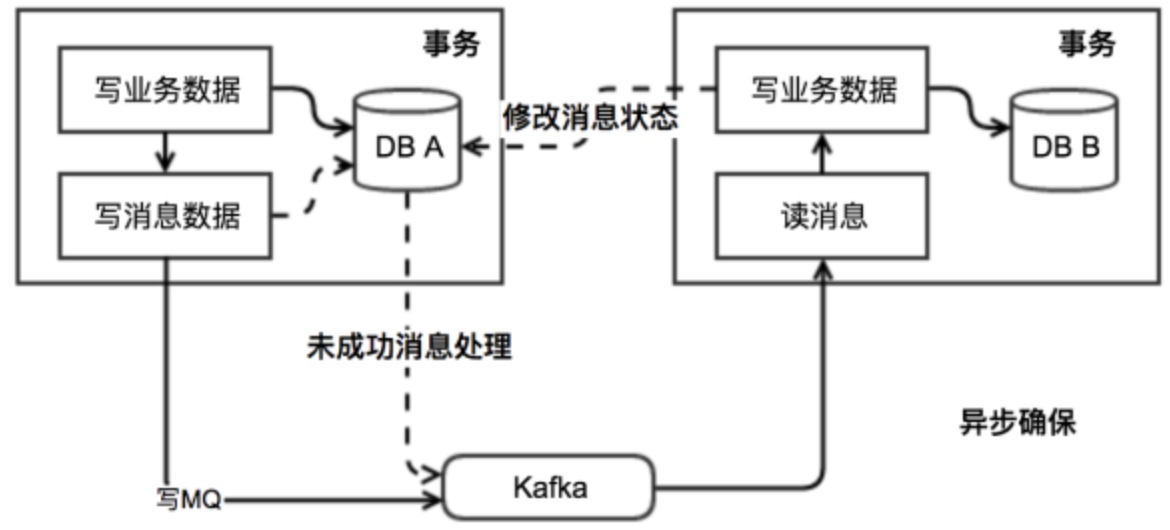
此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
我们首先需要在本地数据新建一张本地消息表,然后我们必须还要一个MQ(不一定是mq,但必须是类似的中间件)。
这个表应该包括这些字段: id, biz_id, biz_type, msg, msg_result, msg_desc,atime,try_count。分别表示uuid,业务id,业务类型,消息内容,消息结果(成功或失败),消息描述,创建时间,重试次数, 其中biz_id,msg_desc字段是可选的。
实现思路为:
- A 系统在自己本地一个事务里操作同时,插入一条数据到消息表;
- 接着 A 系统将这个消息发送到 MQ 中去;
- B 系统接收到消息之后,在一个事务里,往自己本地消息表里插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了,那么此时这个事务会回滚,这样保证不会重复处理消息;
- B 系统执行成功之后,就会更新自己本地消息表的状态以及 A 系统消息表的状态;
- 如果 B 系统处理失败了,那么就不会更新消息表状态,那么此时 A 系统会定时扫描自己的消息表,如果有未处理的消息,会再次发送到 MQ 中去,让 B 再次处理;
- 这个方案保证了最终一致性,哪怕 B 事务失败了,但是 A 会不断重发消息,直到 B 那边成功为止。
这个方案严重依赖于数据库的消息表来管理事务,这样在高并发的情况下难以扩展,同时要在数据库中额外添加一个与实际业务无关的消息表来实现分布式事务,繁琐。
本地消息表核心是把大事务转变为小事务。
例如,用100元去买一瓶水的例子。
- 1.当你扣钱的时候,你需要在你扣钱的服务器上新增加一个本地消息表,你需要把你扣钱和写入减去水的库存到本地消息表放入同一个事务(依靠数据库本地事务保证一致性。
- 2.这个时候有个定时任务去轮询这个本地事务表,把没有发送的消息,扔给商品库存服务器,叫他减去水的库存,到达商品服务器之后这个时候得先写入这个服务器的事务表,然后进行扣减,扣减成功后,更新事务表中的状态。
- 3.商品服务器通过定时任务扫描消息表或者直接通知扣钱服务器,扣钱服务器本地消息表进行状态更新。
- 4.针对一些异常情况,定时扫描未成功处理的消息,进行重新发送,在商品服务器接到消息之后,首先判断是否是重复的,如果已经接收,在判断是否执行,如果执行在马上又进行通知事务,如果未执行,需要重新执行需要由业务保证幂等,也就是不会多扣一瓶水。
本地消息队列是BASE理论,是最终一致模型,适用于对一致性要求不高的。实现这个模型时需要注意重试的幂等。
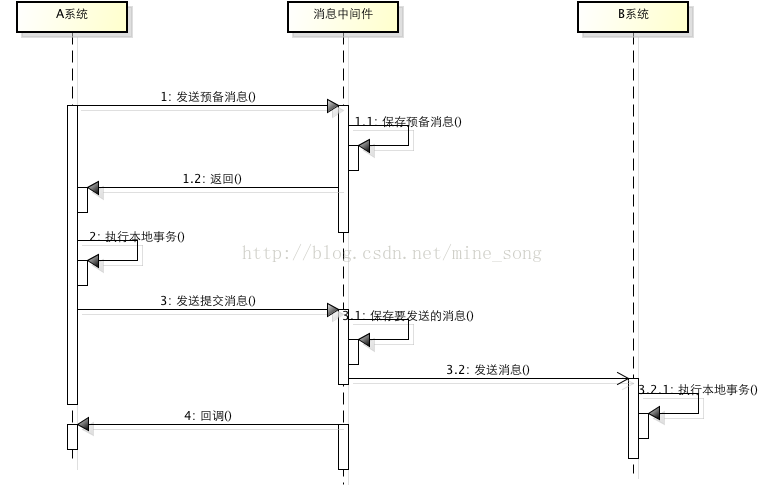
MQ事务
直接基于 MQ 来实现事务,不再用本地的消息表。所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
在RocketMQ中实现了分布式事务,实际上其实是对本地消息表的一个封装,将本地消息表移动到了MQ内部。
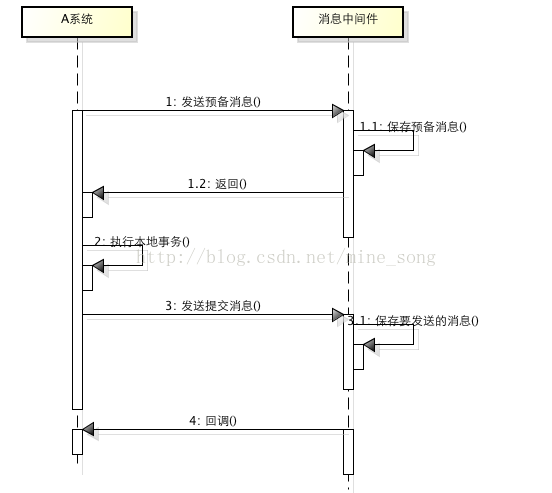
基本流程如下:
- 1、A系统向消息中间件发送一条预备消息
- 2、消息中间件保存预备消息并返回成功
- 3、A执行本地事务
- 4、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
- 步骤一出错,则整个事务失败,不会执行A的本地操作
- 步骤二出错,则整个事务失败,不会执行A的本地操作
- 步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
- 步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。
上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。如果消费超时,则需要一直重试,消息接收端需要保证幂等。如果消息消费失败,这个就需要人工进行处理,因为这个概率较低,如果为了这种小概率时间而设计这个复杂的流程反而得不偿失。
Saga事务
SAGA可以看做一个异步的、利用队列实现的补偿事务。
其适用于无需马上返回业务发起方最终状态的场景,例如:你的请求已提交,请稍后查询或留意通知 之类。
Saga是30年前一篇数据库伦理提到的一个概念。其核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
saga的提出,最早是为了解决可能会长时间运行的分布式事务(long-running process)的问题。所谓long-running的分布式事务,是指那些企业业务流程,需要跨应用、跨企业来完成某个事务,甚至在事务流程中还需要有手工操作的参与,这类事务的完成时间可能以分计,以小时计,甚至可能以天计。这类事务如果按照事务的ACID的要求去设计,势必造成系统的可用性大大的降低。试想一个由两台服务器一起参与的事务,服务器A发起事务,服务器B参与事务,B的事务需要人工参与,所以处理时间可能很长。如果按照ACID的原则,要保持事务的隔离性、一致性,服务器A中发起的事务中使用到的事务资源将会被锁定,不允许其他应用访问到事务过程中的中间结果,直到整个事务被提交或者回滚。这就造成事务A中的资源被长时间锁定,系统的可用性将不可接受。
而saga,则是一种基于补偿的消息驱动的用于解决long-running process的一种解决方案。目标是为了在确保系统高可用的前提下尽量确保数据的一致性。还是上面的例子,如果用saga来实现,那就是这样的流程:服务器A的事务先执行,如果执行顺利,那么事务A就先行提交;如果提交成功,那么就开始执行事务B,如果事务B也执行顺利,则事务B也提交,整个事务就算完成。但是如果事务B执行失败,那事务B本身需要回滚,这时因为事务A已经提交,所以需要执行一个补偿操作,将已经提交的事务A执行的操作作反操作,恢复到未执行前事务A的状态。这样的基于消息驱动的实现思路,就是saga。我们可以看出,saga是牺牲了数据的强一致性,仅仅实现了最终一致性,但是提高了系统整体的可用性。
Saga的组成:
每个Saga由一系列sub-transaction Ti 组成
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果,这里的每个T,都是一个本地事务。
可以看到,和TCC相比,Saga没有“预留 try”动作,它的Ti就是直接提交到库。
Saga的执行顺序有两种:
- T1, T2, T3, …, Tn
- T1, T2, …, Tj, Cj,…, C2, C1,其中0 < j < n
Saga定义了两种恢复策略:
- 向后恢复,即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
- 向前恢复,适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, …, Tj(失败), Tj(重试),…, Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
这里要注意的是,在saga模式中不能保证隔离性,因为没有锁住资源,其他事务依然可以覆盖或者影响当前事务。
拿100元买一瓶水的例子来说,这里定义:
T1=扣100元 T2=给用户加一瓶水 T3=减库存一瓶水
C1=加100元 C2=给用户减一瓶水 C3=给库存加一瓶水
我们一次进行T1,T2,T3如果发生问题,就执行发生问题的C操作的反向。
上面说到的隔离性的问题会出现在,如果执行到T3这个时候需要执行回滚,但是这个用户已经把水喝了(另外一个事务),回滚的时候就会发现,无法给用户减一瓶水了。这就是事务之间没有隔离性的问题
可以看见saga模式没有隔离性的影响还是较大,可以参照华为的解决方案:从业务层面入手加入一 Session 以及锁的机制来保证能够串行化操作资源。也可以在业务层面通过预先冻结资金的方式隔离这部分资源, 最后在业务操作的过程中可以通过及时读取当前状态的方式获取到最新的更新。
具体实例:可以参考华为的 servicecomb 。
参考:
CSharp-ValueTask解析
结构vs类,栈vs堆
在托管.NET世界中,您应该关注两个内存区域:栈和堆。堆是在其中分配所有对象的托管内存(无论何时调用 new YourClass)。重要的方面是它与任何线程都不相关或没有连接。一个线程可以分配一个对象并将其传递给另一线程。只要垃圾收集器没有收集该对象,该对象就会在堆上。
栈以不同的方式工作。它被分配给特定的线程(每个线程的堆栈大小有限)。栈具有框架,可用于分配一些内存,例如用于在调用过程中创建并分配给变量的结构值,例如,通过调用Guid.NewGuid()。
堆分配的内存可用于在线程之间传输某些数据。由于栈是分配给特定线程的,因此不能用于传输某些数据。另一方面,如果您要分配少量内存,则堆栈将更快一些,因为它是线程本地的,并且不会陷入启动垃圾收集器等缓慢的路径中。
Task
Task 在 .NET Framework 4 中 System.Threading.Tasks 命名空间被引入,在 C#5 以及 .NET Framwrok 4.5 中的异步编程模式引入了 async/await。
Task 的核心就是 promise,它表示最终完成的一些操作。当初始化一个操作时,返回一个 Task,当操作完成时,Task 会完成。
特点:
Task 很灵活,并且有很多好处。例如你可以通过多个消费者并行等待多次。你可以存储一个到字典中,以便后面的任意数量的消费者等待,它允许为异步结果像缓存一样使用。如果场景需要,你可以阻塞一个等待完成。并且你可以在这些任务上编写和使用各种操作(就像组合器),例如 WhenAny 操作,它可以异步等待第一个操作完成。
然而,这种灵活性对于大多数情况下是不需要的:仅仅只是调用异步操作并且等待结果:
1 | TResult result = await SomeOperationAsync(); |
副作用:
Task 是一个类。作为一个类,就是说任意操作创建一个 Task 都会分配一个对象,越来越多的对象都会被分配,所以 GC 操作也会越来越频繁,也就会消耗越来越多的资源,本来它应该是去做其他事的。
ValueTask
.NET CORE 2.0 引入了一个新类型 ValueTask<TResult>,在 System.Threading.Tasks.Extensions 命名空间中。ValueTask<TResult> 作为结构体引入的,它是 TResult 或 Task<TResult> 包装器。
实例可以等待或 Task<TResult> 使用 AsTask 转换为。 ValueTask<TResult> 实例仅可等待一次, 并且在实例完成之前, 使用者可能不会调用 GetAwaiter()。
永远不应对 ValueTask<TResult>实例执行以下操作:
1 | 等待实例多次。 |
如果执行上述任一操作, 则结果是不确定的。
同步完成 (synchronous completion)
它能从异步方法返回并且如果这个方法同步成功完成,不需要分配任何内存:只简单的初始化这个 ValueTask<TResult> 结构体,它返回 TResult。
只有当该方法异步完成时,Task<TResult> 才需要进行分配, 创建包装该 ValueTask <TResult> 的实例(以最小化 ValueTask <TResult>的大小,并用于优化成功路径,异步方法未处理的异常故障也将分配一个 Task<TResult>,所以 ValueTask<TResult> 可以简单地包裹该 Task<TResult>, 而并不是 随身携带附加字段以存储异常)。
异步完成 (asynchronous completion)
在.NET Core 2.1,引入 IValueTaskSource<TResult> 支持池化和重用。
.NET Core 2.1为 ValueTask 添加了另一个构造函数:
1 | public readonly struct ValueTask<TResult> |
token:令牌参数,该值确保将 IValueTaskSource 返回到池后不会使用 ValueTask。有效地,此令牌值将传递到 IValueTaskSource 实现的每个方法,该方法能够检查调用者是否滥用 ValueTask。
1 | public interface IValueTaskSource<out TResult> |
参与:
Understanding the Whys, Whats, and Whens of ValueTask
Task, Async Await, ValueTask, IValueTaskSource and how to keep your sanity in modern .NET world
Actor模型和CSP模型
传统三层无状态架构的缺陷
三层架构包括表示层、业务逻辑层(中间层)、数据访问层(存储层)
传统的三层体系结构具有无状态前端、无状态的中间层和存储层,由于存储层的延迟和吞吐量限制,其可扩展性有限(存储层常常会成为系统的瓶颈),因此必须针对每个请求进行咨询。这就意味着整套系统也会因为存储层的限制而变得低效。通常的做法是在中间层与存储层中间加一层缓存逻辑出来,以提升系统性能,但是很快就会遇到存储层与缓存层的数据一致性问题,为了防止缓存项的并发更新导致不一致,应用程序或缓存管理器必须实现并发控制协议。这无疑为开发人员和运维人员增加了额外的工作量。
Actor模型和CSP模型的出现,解决了传统三层架构的缺陷。
Actor模型
Actor模型简介
actor模型最早被1973年的“A Universal Modular ACTOR Formalism for Artificial Intelligence”引入,作为人工智能研究中的一种计算方法。它的最初目标是用一种能安全地跨工作站并发分布的通信方式来建模并行计算。这篇文章几乎没有假设实现细节,而是定义了一种高级消息传递通信模型。actor模型的四个主要变体:经典actor模型、基于进程的actor模型、通信事件循环模型、以及活动对象模型。
有些健壮的工业级actor系统正被用于赋能大规模可伸缩分布式系统,主要案例:例如Akka被用于服务PayPal的十亿级的事务,Erlang被用于为WhatsApp的上亿用户发送消息,而Orleans被用于服务Halo4的数百万玩家。
Actor模型作为一种用于处理并发计算的数学概念模型,它定义了系统组件该如何表现,以及如何与其他组件交互的一些通用规则。它将Actor对象用作并发计算的基本单元,它也是一种重要的软件设计思想,它在架构、设计、实现以及组件之间的消息传递方面有着非常好的应用,也更好的发挥了多核计算机的潜力。该思想与我们经常用到的面向对象语言的思想很类似:一个对象接受消息(方法调用)然后依据消息数据进行计算。主要的不同点在于,actor之间完全独立,没有共享内存。值得注意的是,一个actor维持的私有状态从来不会被其他actor改变,而只会通过接受消息,自己改变自己。通过创建新的Actor对象,可以在计算操作的生命周期中以抽象方式提高系统的分布性。
Actor模型允许建立一个有状态的中间层,其内存级的读写性能和特定于相关领域的业务实体行为,确保了系统的高性能以及数据的一致性。Actor模型天然的拥有着面向对象的程序设计功能,在实践中我们应该把主要精力放到组件之间的消息传递,而不是对象的属性和内部行为。
一个actor并不能成为actor模型。actor是系统的组件,actor模型认为系统所有的组件都是actor,都有地址,actor通过这些地址进行异步通信。
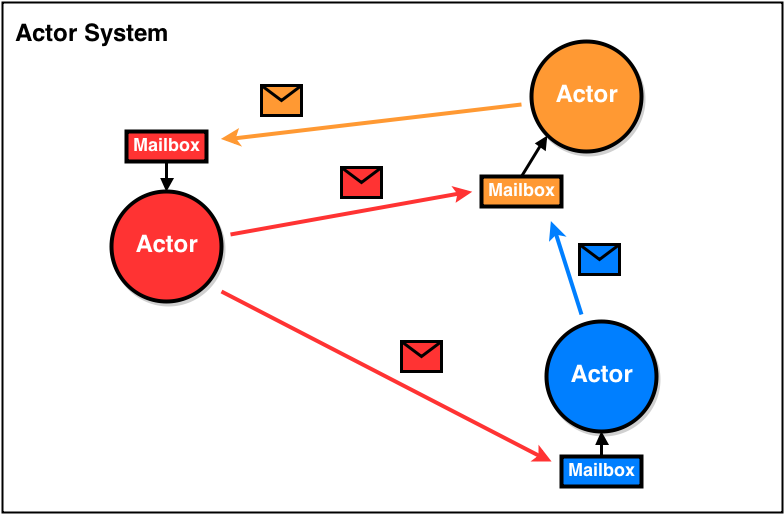
经典actor模型
经典actor模型,保持了在隔离的计算单元和状态单元之间通过消息来做异步通信的思想,主要特点如下:
1 | 异步通信:使消息就像从一个Actor对象传输到了另一个Actor对象 |
当一个actor接收消息时,通常做以下三件事情:
1 | create:用一种行为的描述和一组参数(包括其它actor)来创建一个actor。 |
在经典actor模型中,状态变化均由become操作来聚合完成。每当actor处理一条消息时,它会计算出一个行为,来响应它期望处理的下一种消息类型。become操作的参数是一个有名字的continuation b,表示actor应该被更新为的行为,以及它应该传递给 b 的状态。(continuation:延续)
可以简单理解成,在一个actor维持私有状态之前,第三条基本上意味着定义了接收下条信息之前actor的状态。或者说,actor是如何改变自身状态的。
假设一个actor是一个计算器,初始状态为0。当这个actor接收到“+1”的消息后,它将指定接收下一个消息时,actor的状态为1,而不是改变原始的状态。
Orleans对Actor的应用
Actor平台(例如Erlang和Akka)在简化分布式系统编程方面向前迈了一步。但是,由于提供的抽象和系统服务的水平相对较低,它们仍然使开发人员承担着许多分布式系统的复杂性。主要包括开发用于管理Actor的生命周期,处理分布式簇,处理Actor的失败和恢复,放置Actor以及由此产生的管理分布式资源的应用程序代码。要为应用程序中的这些问题构建正确的解决方案,这就开发人员的要求就非常高了,必须是分布式系统专家级别的。
为了减少这些问题的发生,Orleans框架引入了虚拟Actor的新型抽象,它解决了许多复杂的分布式系统问题,例如可靠性和分布式资源管理,从而使开发人员摆脱了那些麻烦。同时,Orleans运行时使应用程序能够获得高性能,可靠性和可伸缩性。
Orleans对Actor的实现特点:
- 1,Orleans Actor无处不在:无法明确创建或销毁它。它的生命周期超越了其任何内存对象的生命周期,因此也超越了任何特定服务器的生命周期。
- 2,Orleans Actor会自动实例化:如果没有Actor的内存实例,则发送给Actor的消息会促使在可用服务器上创建一个新实例。作为运行时资源管理的一部分,将自动回收未使用的Actor实例。
- 3,Actor永远不会失败:如果服务器崩溃了,下一条发送给运行在故障服务器上的Actor的消息将会促使Orleans自动在另一台服务器上重新实例化该Actor ,从而无需应用程序来监督和显式重新创建已经挂掉的Actor。
- 4,Actor实例的位置对于应用程序代码是透明的,从而大大简化了编程。
- 5,Orleans可以自动创建同一个无状态Actor的多个实例,从而无缝扩展热门Actor。
虚拟Actor的引入,相当于为开发者提供了一个虚拟的内存空间,使开发人员可以调用系统中的任何角色,无论它是否存在于内存中。虚拟化依赖于从虚拟角色映射到当前运行的物理实例的间接寻址。运行时通过一个分布式目录支持间接寻址,该目录将Actor标识映射到其当前物理位置。Orleans通过使用该映射的本地缓存来最小化间接寻址的运行时开销。这个策略被证明是非常有效的。在微软的生产服务中,缓存命中率通常远远超过90%。
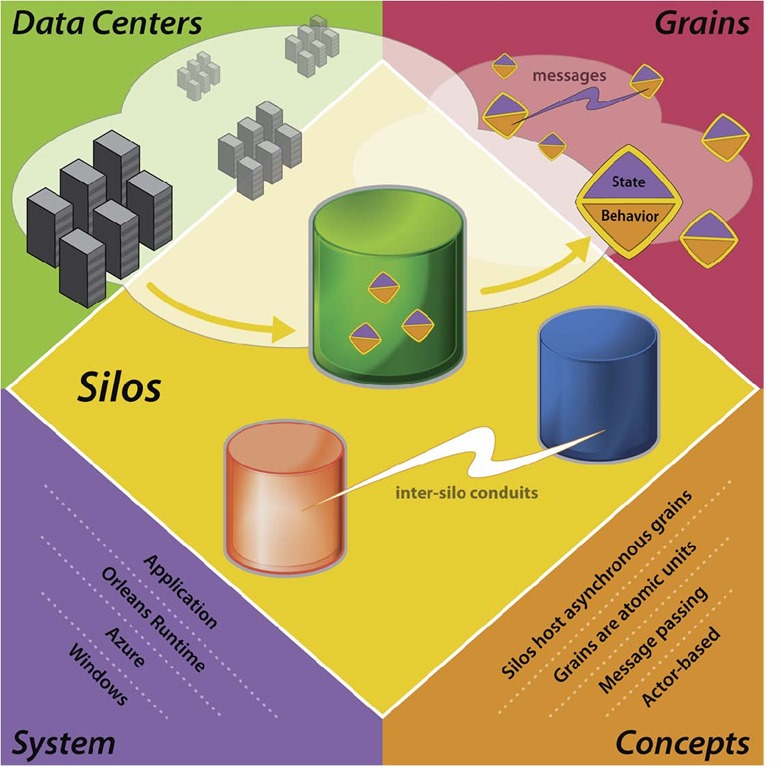
CSP模型
CSP是 Communicating Sequential Processes(通信顺序进程) 的简称。在CSP中,多了一个角色Channel,过程(比如goroutine,Worker1)与过程(Worker2)之间不直接通信,而是通过Channle进行通信。
1 | Worker1 --> Channel --> Worker2 |
CSP模型特点:
- Channel是过程的中间媒介,Worker1想要跟Worker2发信息时,直接把信息放到Channel里(在程序中其实就是一块内存),然后Worker2在方便的时候到Channel里获取。
- Worker1和Worker2之间可以存在很多个Channel;在Golang中每个Channel定义不同的数据类型,即发送不同类型的消息的时候会用到多个不同的Channel。
Go语言的CSP模型是由协程Goroutine与通道Channel实现:
- Go协程goroutine: 是一种轻量线程,它不是操作系统的线程,而是将一个操作系统线程分段使用,通过调度器实现协作式调度。是一种绿色线程,微线程,它与Coroutine协程也有区别,能够在发现堵塞后启动新的微线程。
- 通道channel: 类似Unix的Pipe,用于协程之间通讯和同步。协程之间虽然解耦,但是它们和Channel有着耦合。
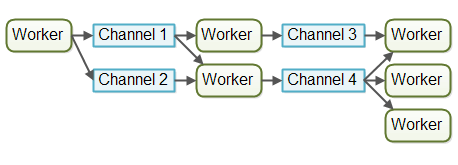
Actor模型和CSP模型比较
Actor之间直接通讯,而CSP是通过Channel通讯,在耦合度上两者是有区别的,后者更加松耦合。
同时,它们都是描述独立的流程通过消息传递进行通信。主要的区别在于:在CSP消息交换是同步的(即两个流程的执行”接触点”的,在此他们交换消息),而Actor模型是完全解耦的,可以在任意的时间将消息发送给任何未经证实的接受者。由于Actor享有更大的相互独立,因为他可以根据自己的状态选择处理哪个传入消息。自主性更大些。
在Go语言中为了不堵塞流程,程序员必须检查不同的传入消息,以便预见确保正确的顺序。CSP好处是Channel不需要缓冲消息,而Actor理论上需要一个无限大小的邮箱作为消息缓冲。
参考:
C-Sharp字符串与字节互转
十六进制
十六进制的表示:
C语言、Shell、Python语言及其他相近的语言使用字首“0x”,例如“0x5A3”。开头的“0”令解析器更易辨认数,而“x”则代表十六进制。在“0x”中的“x”可以大写或小写。
16进制就有16个数,015,用二进制表示15的方法就是1111,从而可以推断出,16进制用2进制可以表现成00001111,顾名思义,也就是每四个为一位。最高位不够可用零代替。
一个字节包含8个二进制位,一个十六进制可表示4个二进制位,所以,一个字节可以由2个十六进制表示。即,一个byte 对应两位十六进制位。
十六进制转换
字符串转为16进制字符
1 | public static string StringToHexString(string s, Encoding encode) |
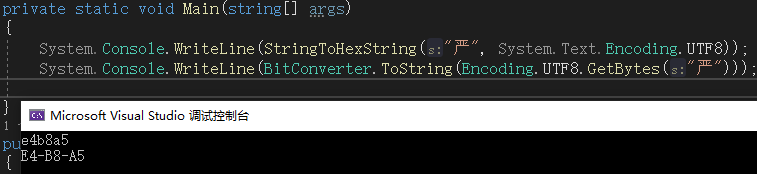
16进制字符串转为字符串
1 | public static string HexStringToString(string hs, Encoding encode) |
byte[]转为16进制字符串
1 | public static string ByteToHexStr(byte[] bytes) |
16进制的字符串转为byte[]
1 | public static byte[] StrToToHexByte(string hexString) |
参考:
工具集合
UltraEdit
文本编辑器,可以查看16进制字节;
ef core power tool
生成DbContext;反向生成 POCO 类等;
emeditor
大文本文件编辑器,方便查找;
ListDLLs
检测当前运行的进程已经加载的dll文件
WinHex
是在Windows下执行的十六进制编辑软件,此软件功能很强大,有完好的分区管理功能和文件管理功能。能自己主动分析分区链和文件簇链。能对硬盘进行不同方式不同程度的备份。甚至克隆整个硬盘;它可以编辑不论什么一种文件类型的二进制内容(用十六进制显示)其磁盘编辑器可以编辑物理磁盘或逻辑磁盘的随意扇区。是手工恢复数据的首选工具软件。
PEid
PEiD(PE Identifier)是一款著名的查壳工具,其功能强大,几乎可以侦测出所有的壳,其数量已超过470 种PE 文档 的加壳类型和签名。
cmder
命令行增强工具
VLC mediaplayer
视频流播放软件
字符编码笔记
ASCII 码
每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
ASCII,美国信息交换标准代码,是基于拉丁字母的一套电脑编码系统。
参考:ASCII对照表
Unicode 与 UCS
Unicode也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是”Universal Multiple-Octet Coded Character Set”,简称为UCS。UCS可以看作是”Unicode Character Set”的缩写。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。
UTF编码
UTF-8就是以8位为单元对UCS进行编码。从UCS-2到UTF-8的编码方式如下:
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
|---|---|
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
BOM
BOM —— Byte Order Mark,中文名译作“字节顺序标记”。在这里找到一段关于 BOM 的说明:
在UCS 编码中有一个叫做 “Zero Width No-Break Space” ,中文译名作“零宽无间断间隔”的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。
UCS 规范建议我们在传输字节流前,先传输字符 “Zero Width No-Break Space”。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到FFFE,就表明这个字节流是 Little- Endian 的。因此字符 “Zero Width No-Break Space” (“零宽无间断间隔”)又被称作 BOM。
UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 “Zero Width No-Break Space” 的 UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8 编码了。Windows 就是使用 BOM 来标记文本文件的编码方式的。
UTF-8
UTF-8的一个特别的好处是它与ISO-8859-1完全兼容。UTF是 UCS Transformation Format 的缩写。
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
UCS-2、UCS-4、BMP
CS有两种格式:UCS-2和UCS-4。顾名思义,UCS-2就是用两个字节编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码。下面让我们做一些简单的数学游戏:
UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位。
UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个plane。每个plane根据第3个字节分为256行 (rows),每行包含256个cells。当然同一行的cells只是最后一个字节不同,其余都相同。
group 0的plane 0被称作 Basic Multilingual Plane, 即BMP。或者说UCS-4中,高两个字节为0的码位被称作BMP。
将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
Unicode 与 UTF-8 之间的转换
Windows平台,有一个最简单的转化方法,就是使用内置的记事本小程序notepad.exe。打开文件后,点击文件菜单中的另存为命令,会跳出一个对话框,在最底部有一个编码的下拉条。
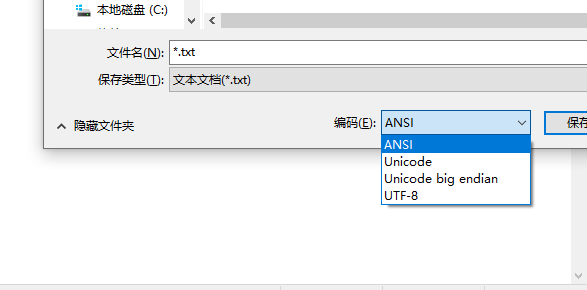
里面有四个选项:ANSI,Unicode,Unicode big endian和UTF-8。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对 Windows 简体中文版,如果是繁体中文版会采用 Big5 码)。
2)Unicode编码这里指的是notepad.exe使用的 UCS-2 编码方式,即直接用两个字节存入字符的 Unicode 码,这个选项用的 little endian 格式。
3)Unicode big endian编码与上一个选项相对应。
4)UTF-8编码,也就是上一节谈到的编码方法。
选择完”编码方式”后,点击”保存”按钮,文件的编码方式就立刻转换好了。
Little endian (LE) 和 Big endian (BE)
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格”(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
对照表:
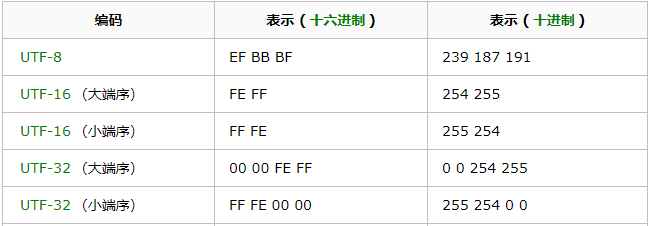
示例:
用文本编辑软件UltraEdit 中的”十六进制功能”,观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节D1 CF,这正是严的 GB2312 编码,这也暗示 GB2312 是采用大头方式存储的。
2)Unicode:编码是四个字节FF FE 25 4E,其中FF FE表明是小头方式存储,真正的编码是4E 25。
3)Unicode big endian:编码是四个字节FE FF 4E 25,其中FE FF表明是大头方式存储。
4)UTF-8:编码是六个字节EF BB BF E4 B8 A5,前三个字节EF BB BF表示这是UTF-8编码,后三个E4 B8 A5就是严的具体编码,它的存储顺序与编码顺序是一致的。
参考:
bit(比特) 和 Byte(字节)
bit(比特)
bit 是信息量的单位,是表示信息的最小单位,只有两种状态:0和1。二进制的一位,就叫做 1 bit。
它的简写为小写字母 “b”。
Byte (字节)
表示一个 8 位无符号整数。
即,8 bit(比特位)= 1 Byte(字节);
bit(比特)与 Byte (字节) 的关系
1 | 1MB = 1024KB = 1024 * 1024B = 1048576B; |

例如:
根据 一字节 等于 8 比特的 换算方法,就可以得出以下结论。
下载速度从理论上来说,应该是 带宽的 八分之一。
2M 宽带理论下载速度是 256 KB
10M 宽带理论下载速度是 1280 KB
总结:
存储单位和网速的单位,不管是 B 还是 b,代表的都是 字节 Byte。
带宽的单位,不管是 B 还是 b,代表的都是 比特 bit 。
参考:
CSharp位运算与移位运算
移位运算符仅针对 int、uint、long 和 ulong 类型定义,因此运算的结果始终包含至少 32 位。 如果左侧操作数是其他整数类型(sbyte、byte、short、ushort 或 char),则其值将转换为 int 类型。
左移位运算符 <<
<< 运算符将其左侧操作数向左移动右侧操作数定义的位数。
左移运算会放弃超出结果类型范围的高阶位,并将低阶空位位置设置为零
1 | uint x = 0b_1100_1001_0000_0000_0000_0000_0001_0001; |
总结:左移相当于 X * 2的N次方 (乘以 2 的N次方)
1 | x<<1= x*2 |
右移位运算符 >>
>> 运算符将其左侧操作数向右移动右侧操作数定义的位数。
右移位运算会放弃低阶位。
1 | uint x = 0b_1001; |
总结:左移相当于 X / 2的N次方 (除以 2 的N次方)
1 | x>>1= x/2 |
参考: